查询分析
查询执行的统计
查询执行的统计
本文档主要介绍Doris在查询执行的统计结果。利用这些统计的信息,可以更好的帮助我们了解Doris的执行情况,并有针对性的进行相应Debug与调优工作。
也可以参考如下语法在命令行中查看导入和查询的 Profile:
名词解释
- FE:Frontend,Doris 的前端节点。负责元数据管理和请求接入。
- BE:Backend,Doris 的后端节点。负责查询执行和数据存储。
- Fragment:FE会将具体的SQL语句的执行转化为对应的Fragment并下发到BE进行执行。BE上执行对应Fragment,并将结果汇聚返回给FE。
基本原理
FE将查询计划拆分成为Fragment下发到BE进行任务执行。BE在执行Fragment时记录了运行状态时的统计值,并将Fragment执行的统计信息输出到日志之中。 FE也可以通过开关将各个Fragment记录的这些统计值进行搜集,并在FE的Web页面上打印结果。
操作流程
通过Mysql命令,将FE上的Report的开关打开
mysql> set enable_profile=true;
之后执行对应的SQL语句之后(旧版本为is_report_success),在FE的Web页面就可以看到对应SQL语句执行的Report信息:
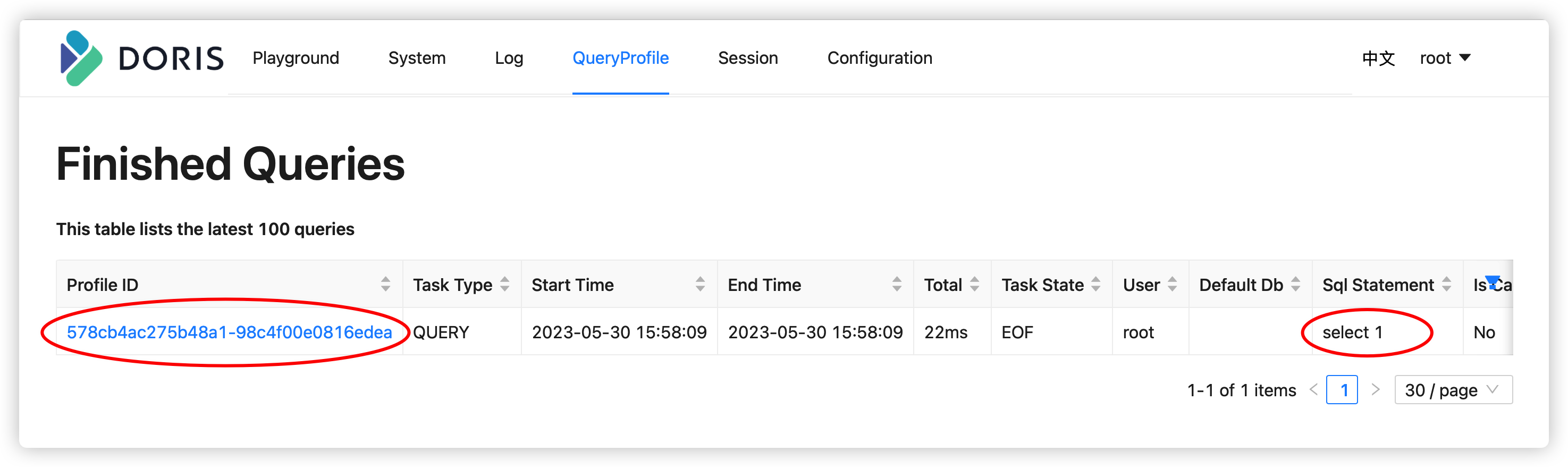
这里会列出最新执行完成的100条语句,我们可以通过Profile查看详细的统计信息。
Query:
Summary:
Query ID: 9664061c57e84404-85ae111b8ba7e83a
Start Time: 2020-05-02 10:34:57
End Time: 2020-05-02 10:35:08
Total: 10s323ms
Query Type: Query
Query State: EOF
Doris Version: trunk
User: root
Default Db: default_cluster:test
Sql Statement: select max(Bid_Price) from quotes group by Symbol
这里详尽的列出了查询的ID,执行时间,执行语句等等的总结信息。接下来内容是打印从BE收集到的各个Fragment的详细信息。
Fragment 0:
Instance 9664061c57e84404-85ae111b8ba7e83d (host=TNetworkAddress(hostname:192.168.0.1, port:9060)):(Active: 10s270ms, % non-child: 0.14%)
- MemoryLimit: 2.00 GB
- BytesReceived: 168.08 KB
- PeakUsedReservation: 0.00
- SendersBlockedTimer: 0ns
- DeserializeRowBatchTimer: 501.975us
- PeakMemoryUsage: 577.04 KB
- RowsProduced: 8.322K (8322)
EXCHANGE_NODE (id=4):(Active: 10s256ms, % non-child: 99.35%)
- ConvertRowBatchTime: 180.171us
- PeakMemoryUsage: 0.00
- RowsReturned: 8.322K (8322)
- MemoryUsed: 0.00
- RowsReturnedRate: 811
这里列出了Fragment的ID;hostname指的是执行Fragment的BE节点;Active:10s270ms表示该节点的执行总时间;non-child: 0.14%表示执行节点自身的执行时间(不包含子节点的执行时间)占总时间的百分比;
PeakMemoryUsage表示EXCHANGE_NODE内存使用的峰值;RowsReturned表示EXCHANGE_NODE结果返回的行数;RowsReturnedRate=RowsReturned/ActiveTime;这三个统计信息在其他NODE中的含义相同。
后续依次打印子节点的统计信息,这里可以通过缩进区分节点之间的父子关系。
Profile参数解析
BE端收集的统计信息较多,下面列出了各个参数的对应含义:
Fragment
- AverageThreadTokens: 执行Fragment使用线程数目,不包含线程池的使用情况
- Buffer Pool PeakReservation: Buffer Pool使用的内存的峰值
- MemoryLimit: 查询时的内存限制
- PeakMemoryUsage: 整个Instance在查询时内存使用的峰值
- RowsProduced: 处理列的行数
BlockMgr
- BlocksCreated: BlockMgr创建的Blocks数目
- BlocksRecycled: 重用的Blocks数目
- BytesWritten: 总的落盘写数据量
- MaxBlockSize: 单个Block的大小
- TotalReadBlockTime: 读Block的总耗时
DataStreamSender
- BytesSent: 发送的总数据量 = 接受者 * 发送数据量
- IgnoreRows: 过滤的行数
- LocalBytesSent: 数据在Exchange过程中,记录本机节点的自发自收数据量
- OverallThroughput: 总的吞吐量 = BytesSent / 时间
- SerializeBatchTime: 发送数据序列化消耗的时间
- UncompressedRowBatchSize: 发送数据压缩前的RowBatch的大小
ODBC_TABLE_SINK
- NumSentRows: 写入外表的总行数
- TupleConvertTime: 发送数据序列化为Insert语句的耗时
- ResultSendTime: 通过ODBC Driver写入的耗时
EXCHANGE_NODE
- BytesReceived: 通过网络接收的数据量大小
- MergeGetNext: 当下层节点存在排序时,会在EXCHANGE NODE进行统一的归并排序,输出有序结果。该指标记录了Merge排序的总耗时,包含了MergeGetNextBatch耗时。
- MergeGetNextBatch:Merge节点取数据的耗时,如果为单层Merge排序,则取数据的对象为网络队列。若为多层Merge排序取数据对象为Child Merger。
- ChildMergeGetNext: 当下层的发送数据的Sender过多时,单线程的Merge会成为性能瓶颈,Doris会启动多个Child Merge线程并行归并排序。记录了Child Merge的排序耗时 该数值是多个线程的累加值。
- ChildMergeGetNextBatch: Child Merge节点从取数据的耗时,如果耗时过大,可能的瓶颈为下层的数据发送节点。
- DataArrivalWaitTime: 等待Sender发送数据的总时间
- FirstBatchArrivalWaitTime: 等待第一个batch从Sender获取的时间
- DeserializeRowBatchTimer: 反序列化网络数据的耗时
- SendersBlockedTotalTimer(*): DataStreamRecv的队列的内存被打满,Sender端等待的耗时
- ConvertRowBatchTime: 接收数据转为RowBatch的耗时
- RowsReturned: 接收行的数目
- RowsReturnedRate: 接收行的速率
SORT_NODE
- InMemorySortTime: 内存之中的排序耗时
- InitialRunsCreated: 初始化排序的趟数(如果内存排序的话,该数为1)
- SortDataSize: 总的排序数据量
- MergeGetNext: MergeSort从多个sort_run获取下一个batch的耗时 (仅在落盘时计时)
- MergeGetNextBatch: MergeSort提取下一个sort_run的batch的耗时 (仅在落盘时计时)
- TotalMergesPerformed: 进行外排merge的次数
AGGREGATION_NODE
- PartitionsCreated: 聚合查询拆分成Partition的个数
- GetResultsTime: 从各个partition之中获取聚合结果的时间
- HTResizeTime: HashTable进行resize消耗的时间
- HTResize: HashTable进行resize的次数
- HashBuckets: HashTable中Buckets的个数
- HashBucketsWithDuplicate: HashTable有DuplicateNode的Buckets的个数
- HashCollisions: HashTable产生哈希冲突的次数
- HashDuplicateNodes: HashTable出现Buckets相同DuplicateNode的个数
- HashFailedProbe: HashTable Probe操作失败的次数
- HashFilledBuckets: HashTable填入数据的Buckets数目
- HashProbe: HashTable查询的次数
- HashTravelLength: HashTable查询时移动的步数
HASH_JOIN_NODE
- ExecOption: 对右孩子构造HashTable的方式(同步or异步),Join中右孩子可能是表或子查询,左孩子同理
- BuildBuckets: HashTable中Buckets的个数
- BuildRows: HashTable的行数
- BuildTime: 构造HashTable的耗时
- LoadFactor: HashTable的负载因子(即非空Buckets的数量)
- ProbeRows: 遍历左孩子进行Hash Probe的行数
- ProbeTime: 遍历左孩子进行Hash Probe的耗时,不包括对左孩子RowBatch调用GetNext的耗时
- PushDownComputeTime: 谓词下推条件计算耗时
- PushDownTime: 谓词下推的总耗时,Join时对满足要求的右孩子,转为左孩子的in查询
CROSS_JOIN_NODE
- ExecOption: 对右孩子构造RowBatchList的方式(同步or异步)
- BuildRows: RowBatchList的行数(即右孩子的行数)
- BuildTime: 构造RowBatchList的耗时
- LeftChildRows: 左孩子的行数
- LeftChildTime: 遍历左孩子,和右孩子求笛卡尔积的耗时,不包括对左孩子RowBatch调用GetNext的耗时
UNION_NODE
- MaterializeExprsEvaluateTime: Union两端字段类型不一致时,类型转换表达式计算及物化结果的耗时
ANALYTIC_EVAL_NODE
- EvaluationTime: 分析函数(窗口函数)计算总耗时
- GetNewBlockTime: 初始化时申请一个新的Block的耗时,Block用来缓存Rows窗口或整个分区,用于分析函数计算
- PinTime: 后续申请新的Block或将写入磁盘的Block重新读取回内存的耗时
- UnpinTime: 对暂不需要使用的Block或当前操作符内存压力大时,将Block的数据刷入磁盘的耗时
OLAP_SCAN_NODE
OLAP_SCAN_NODE 节点负责具体的数据扫描任务。一个 OLAP_SCAN_NODE 会生成一个或多个 OlapScanner 。每个 Scanner 线程负责扫描部分数据。
查询中的部分或全部谓词条件会推送给 OLAP_SCAN_NODE。这些谓词条件中一部分会继续下推给存储引擎,以便利用存储引擎的索引进行数据过滤。另一部分会保留在 OLAP_SCAN_NODE 中,用于过滤从存储引擎中返回的数据。
OLAP_SCAN_NODE 节点的 Profile 通常用于分析数据扫描的效率,依据调用关系分为 OLAP_SCAN_NODE、OlapScanner、SegmentIterator 三层。
一个典型的 OLAP_SCAN_NODE 节点的 Profile 如下。部分指标会因存储格式的不同(V1 或 V2)而有不同含义。
OLAP_SCAN_NODE (id=0):(Active: 1.2ms, % non-child: 0.00%)
- BytesRead: 265.00 B # 从数据文件中读取到的数据量。假设读取到了是10个32位整型,则数据量为 10 * 4B = 40 Bytes。这个数据仅表示数据在内存中全展开的大小,并不代表实际的 IO 大小。
- NumDiskAccess: 1 # 该 ScanNode 节点涉及到的磁盘数量。
- NumScanners: 20 # 该 ScanNode 生成的 Scanner 数量。
- PeakMemoryUsage: 0.00 # 查询时内存使用的峰值,暂未使用
- RowsRead: 7 # 从存储引擎返回到 Scanner 的行数,不包括经 Scanner 过滤的行数。
- RowsReturned: 7 # 从 ScanNode 返回给上层节点的行数。
- RowsReturnedRate: 6.979K /sec # RowsReturned/ActiveTime
- TabletCount : 20 # 该 ScanNode 涉及的 Tablet 数量。
- TotalReadThroughput: 74.70 KB/sec # BytesRead除以该节点运行的总时间(从Open到Close),对于IO受限的查询,接近磁盘的总吞吐量。
- ScannerBatchWaitTime: 426.886us # 用于统计transfer 线程等待scanner 线程返回rowbatch的时间。在Pipeline调度中,此值无意义。
- ScannerWorkerWaitTime: 17.745us # 用于统计scanner thread 等待线程池中可用工作线程的时间。
OlapScanner:
- BlockConvertTime: 8.941us # 将向量化Block转换为行结构的 RowBlock 的耗时。向量化 Block 在 V1 中为 VectorizedRowBatch,V2中为 RowBlockV2。
- BlockFetchTime: 468.974us # Rowset Reader 获取 Block 的时间。
- ReaderInitTime: 5.475ms # OlapScanner 初始化 Reader 的时间。V1 中包括组建 MergeHeap 的时间。V2 中包括生成各级 Iterator 并读取第一组Block的时间。
- RowsDelFiltered: 0 # 包括根据 Tablet 中存在的 Delete 信息过滤掉的行数,以及 unique key 模型下对被标记的删除行过滤的行数。
- RowsPushedCondFiltered: 0 # 根据传递下推的谓词过滤掉的条件,比如 Join 计算中从 BuildTable 传递给 ProbeTable 的条件。该数值不准确,因为如果过滤效果差,就不再过滤了。
- ScanTime: 39.24us # 从 ScanNode 返回给上层节点的时间。
- ShowHintsTime_V1: 0ns # V2 中无意义。V1 中读取部分数据来进行 ScanRange 的切分。
SegmentIterator:
- BitmapIndexFilterTimer: 779ns # 利用 bitmap 索引过滤数据的耗时。
- BlockLoadTime: 415.925us # SegmentReader(V1) 或 SegmentIterator(V2) 获取 block 的时间。
- BlockSeekCount: 12 # 读取 Segment 时进行 block seek 的次数。
- BlockSeekTime: 222.556us # 读取 Segment 时进行 block seek 的耗时。
- BlocksLoad: 6 # 读取 Block 的数量
- CachedPagesNum: 30 # 仅 V2 中,当开启 PageCache 后,命中 Cache 的 Page 数量。
- CompressedBytesRead: 0.00 # V1 中,从文件中读取的解压前的数据大小。V2 中,读取到的没有命中 PageCache 的 Page 的压缩前的大小。
- DecompressorTimer: 0ns # 数据解压耗时。
- IOTimer: 0ns # 实际从操作系统读取数据的 IO 时间。
- IndexLoadTime_V1: 0ns # 仅 V1 中,读取 Index Stream 的耗时。
- NumSegmentFiltered: 0 # 在生成 Segment Iterator 时,通过列统计信息和查询条件,完全过滤掉的 Segment 数量。
- NumSegmentTotal: 6 # 查询涉及的所有 Segment 数量。
- RawRowsRead: 7 # 存储引擎中读取的原始行数。详情见下文。
- RowsBitmapIndexFiltered: 0 # 仅 V2 中,通过 Bitmap 索引过滤掉的行数。
- RowsBloomFilterFiltered: 0 # 仅 V2 中,通过 BloomFilter 索引过滤掉的行数。
- RowsKeyRangeFiltered: 0 # 仅 V2 中,通过 SortkeyIndex 索引过滤掉的行数。
- RowsStatsFiltered: 0 # V2 中,通过 ZoneMap 索引过滤掉的行数,包含删除条件。V1 中还包含通过 BloomFilter 过滤掉的行数。
- RowsConditionsFiltered: 0 # 仅 V2 中,通过各种列索引过滤掉的行数。
- RowsVectorPredFiltered: 0 # 通过向量化条件过滤操作过滤掉的行数。
- TotalPagesNum: 30 # 仅 V2 中,读取的总 Page 数量。
- UncompressedBytesRead: 0.00 # V1 中为读取的数据文件解压后的大小(如果文件无需解压,则直接统计文件大小)。V2 中,仅统计未命中 PageCache 的 Page 解压后的大小(如果Page无需解压,直接统计Page大小)
- VectorPredEvalTime: 0ns # 向量化条件过滤操作的耗时。
- ShortPredEvalTime: 0ns # 短路谓词过滤操作的耗时。
- PredColumnReadTime: 0ns # 谓词列读取的耗时。
- LazyReadTime: 0ns # 非谓词列读取的耗时。
- OutputColumnTime: 0ns # 物化列的耗时。
通过 Profile 中数据行数相关指标可以推断谓词条件下推和索引使用情况。以下仅针对 Segment V2 格式数据读取流程中的 Profile 进行说明。Segment V1 格式中,这些指标的含义略有不同。
- 当读取一个 V2 格式的 Segment 时,若查询存在 key_ranges(前缀key组成的查询范围),首先通过 SortkeyIndex 索引过滤数据,过滤的行数记录在
RowsKeyRangeFiltered。 - 之后,对查询条件中含有 bitmap 索引的列,使用 Bitmap 索引进行精确过滤,过滤的行数记录在
RowsBitmapIndexFiltered。 - 之后,按查询条件中的等值(eq,in,is)条件,使用BloomFilter索引过滤数据,记录在
RowsBloomFilterFiltered。RowsBloomFilterFiltered的值是 Segment 的总行数(而不是Bitmap索引过滤后的行数)和经过 BloomFilter 过滤后剩余行数的差值,因此 BloomFilter 过滤的数据可能会和 Bitmap 过滤的数据有重叠。 - 之后,按查询条件和删除条件,使用 ZoneMap 索引过滤数据,记录在
RowsStatsFiltered。 RowsConditionsFiltered是各种索引过滤的行数,包含了RowsBloomFilterFiltered和RowsStatsFiltered的值。- 至此 Init 阶段完成,Next 阶段删除条件过滤的行数,记录在
RowsDelFiltered。因此删除条件实际过滤的行数,分别记录在RowsStatsFiltered和RowsDelFiltered中。 RawRowsRead是经过上述过滤后,最终需要读取的行数。RowsRead是最终返回给 Scanner 的行数。RowsRead通常小于RawRowsRead,是因为从存储引擎返回到 Scanner,可能会经过一次数据聚合。如果RawRowsRead和RowsRead差距较大,则说明大量的行被聚合,而聚合可能比较耗时。RowsReturned是 ScanNode 最终返回给上层节点的行数。RowsReturned通常也会小于RowsRead。因为在 Scanner 上会有一些没有下推给存储引擎的谓词条件,会进行一次过滤。如果RowsRead和RowsReturned差距较大,则说明很多行在 Scanner 中进行了过滤。这说明很多选择度高的谓词条件并没有推送给存储引擎。而在 Scanner 中的过滤效率会比在存储引擎中过滤效率差。
通过以上指标,可以大致分析出存储引擎处理的行数以及最终过滤后的结果行数大小。通过 Rows***Filtered 这组指标,也可以分析查询条件是否下推到了存储引擎,以及不同索引的过滤效果。此外还可以通过以下几个方面进行简单的分析。
OlapScanner下的很多指标,如IOTimer,BlockFetchTime等都是所有 Scanner 线程指标的累加,因此数值可能会比较大。并且因为 Scanner 线程是异步读取数据的,所以这些累加指标只能反映 Scanner 累加的工作时间,并不直接代表 ScanNode 的耗时。ScanNode 在整个查询计划中的耗时占比为Active字段记录的值。有时会出现比如IOTimer有几十秒,而Active实际只有几秒钟。这种情况通常因为:IOTimer为多个 Scanner 的累加时间,而 Scanner 数量较多。- 上层节点比较耗时。比如上层节点耗时 100秒,而底层 ScanNode 只需 10秒。则反映在
Active的字段可能只有几毫秒。因为在上层处理数据的同时,ScanNode 已经异步的进行了数据扫描并准备好了数据。当上层节点从 ScanNode 获取数据时,可以获取到已经准备好的数据,因此 Active 时间很短。
NumScanners表示 Scanner 提交到线程池的Task个数,由RuntimeState中的线程池调度,doris_scanner_thread_pool_thread_num和doris_scanner_thread_pool_queue_size两个参数分别控制线程池的大小和队列长度。线程数过多或过少都会影响查询效率。同时可以用一些汇总指标除以线程数来大致的估算每个线程的耗时。TabletCount表示需要扫描的 tablet 数量。数量过多可能意味着需要大量的随机读取和数据合并操作。UncompressedBytesRead间接反映了读取的数据量。如果该数值较大,说明可能有大量的 IO 操作。CachedPagesNum和TotalPagesNum可以查看命中 PageCache 的情况。命中率越高,说明 IO 和解压操作耗时越少。
Buffer pool
- AllocTime: 内存分配耗时
- CumulativeAllocationBytes: 累计内存分配的量
- CumulativeAllocations: 累计的内存分配次数
- PeakReservation: Reservation的峰值
- PeakUnpinnedBytes: unpin的内存数据量
- PeakUsedReservation: Reservation的内存使用量
- ReservationLimit: BufferPool的Reservation的限制量
