Workload Group
Workload Group 是一种进程内实现的对负载进行逻辑隔离的机制,它通过对BE进程内的资源(CPU,IO,Memory)进行细粒度的划分或者限制,达到资源隔离的目的,它的原理如下图所示:
目前支持的隔离能力包括:
- 管理CPU资源,支持CPU硬限和CPU软限;
- 管理内存资源,支持内存硬限和内存软限;
- 管理IO资源,包括读本地文件和远程文件产生的IO。
版本说明
-
自 Doris 2.0 版本开始提供 Workload Group 功能。在 Doris 2.0 版本中,Workload Group 功能不依赖于 CGroup,而 Doris 2.1 版本中需要依赖 CGroup。
-
从 Doris 1.2 升级到 2.0:建议集群升级完成后,再开启 Workload Group功能。只升级部分 follower FE 节点,可能会因为未升级的 FE 节点没有 Workload Group 的元数据信息,导致已升级的 follower FE 节点查询失败。
-
从 Doris 2.0 升级到 2.1:由于 2.1 版本的 Workload Group 功能依赖于 CGroup,需要先配置 CGroup 环境,再升级到 Doris 2.1 版本。
配置workload group
配置 CGroup 环境
Workload Group 支持对于 CPU , 内存, IO 资源的管理,其中对于 CPU 的管理依赖 CGroup 组件;如果期望使用 Workload Group 管理CPU资源,那么首先需要进行 CGroup 环境的配置。
以下为CGroup环境配置流程:
- 首先确认 BE 所在节点是否已经安装好 GGroup,输出结果中
cgroup代表目前的环境已经安装CGroup V1,cgroup2代表目前的环境已安装CGroup V2,至于具体是哪个版本生效,可以通过下一步确认。
cat /proc/filesystems | grep cgroup
nodev cgroup
nodev cgroup2
nodev cgroupfs
- 通过路径名称可以确认目前生效的 CGroup 版本。
如果存在这个路径说明目前生效的是cgroup v1
/sys/fs/cgroup/cpu/
如果存在这个路径说明目前生效的是cgroup v2
/sys/fs/cgroup/cgroup.controllers
- 在 CGroup 路径下新建一个名为 doris 的目录,这个目录名用户可以自行指定
如果是cgroup v1就在cpu目录下新建
mkdir /sys/fs/cgroup/cpu/doris
如果是cgroup v2就在直接在cgroup目录下新建
mkdir /sys/fs/cgroup/doris
- 需要保证 Doris 的 BE 进程对于这个目录有读/写/执行权限
// 如果是CGroup v1,那么命令如下:
// 1. 修改这个目录的权限为可读可写可执行
chmod 770 /sys/fs/cgroup/cpu/doris
// 2. 把这个目录的归属划分给doris的账户
chown -R doris:doris /sys/fs/cgroup/cpu/doris
// 如果是CGroup v2,那么命令如下:
// 1. 修改这个目录的权限为可读可写可执行
chmod 770 /sys/fs/cgroup/doris
// 2. 把这个目录的归属划分给doris的账户
chown -R doris:doris /sys/fs/cgroup/doris
- 如果目前环境里生效的是CGroup v2版本,那么还需要做以下操作。这是因为CGroup v2对于权限管控比较严格,需要具备根目录的cgroup.procs文件的写权限才能实现进程在group之间的移动。 如果是CGroup v1那么不需要这一步。
chmod a+w /sys/fs/cgroup/cgroup.procs
- 修改 BE 的配置,指定 cgroup 的路径
如果是Cgroup v1,那么配置路径如下
doris_cgroup_cpu_path = /sys/fs/cgroup/cpu/doris
如果是Cgroup v2,那么配置路径如下
doris_cgroup_cpu_path = /sys/fs/cgroup/doris
- 重启 BE,在日志(be.INFO)可以看到"add thread xxx to group"的字样代表配置成功
- 建议单台机器上只部署一个 BE 实例,目前的 Workload Group 功能不支持一个机器上部署多个 BE ;
- 当机器重启之后,CGroup 路径下的所有配置就会清空。如果期望CGroup配置持久化,可以使用 systemd 把操作设置成系统的自定义服务,这样在每次机器重启的时可以自动完成创建和授权操作
- 如果是在容器内使用 CGroup,需要容器具备操作宿主机的权限。
在容器中使用Workload Group的注意事项
Workload的CPU管理是基于CGroup实现的,如果期望在容器中使用Workload Group,那么需要以特权模式启动容器,容器内的Doris进程才能具备读写宿主机CGroup文件的权限。 当Doris在容器内运行时,Workload Group的CPU资源用量是在容器可用资源的情况下再划分的,例如宿主机整机是64核,容器被分配了8个核的资源,Workload Group配置的CPU硬限为50%, 那么Workload Group实际可用核数为4个(8核 * 50%)。
WorkloadGroup的内存管理和IO管理功能是Doris内部实现,不依赖外部组件,因此在容器和物理机上部署使用并没有区别。
如果要在K8S上使用Doris,建议使用Doris Operator进行部署,可以屏蔽底层的权限细节问题。
创建Workload Group
mysql [information_schema]>create workload group if not exists g1
-> properties (
-> "cpu_share"="1024"
-> );
Query OK, 0 rows affected (0.03 sec)
可以参考 CREATE-WORKLOAD-GROUP。
此时配置的 CPU 限制为软限。自 2.1 版本起,系统会自动创建一个名为normal的 group,不可删除。
Workload Group属性
| 属性名称 | 数据类型 | 默认值 | 取值范围 | 说明 |
|---|---|---|---|---|
| cpu_share | 整型 | -1 | [1, 10000] | 可选,CPU软限模式下生效,取值范围和使用的CGroup版本有关,下文有详细描述。cpu_share 代表了 Workload Group 可获得CPU时间的权重,值越大,可获得的CPU时间越多。例如,用户创建了 3 个 Workload Group g-a、g-b 和 g-c,cpu_share 分别为 10、30、40,某一时刻 g-a 和 g-b 正在跑任务,而 g-c 没有任务,此时 g-a 可获得 25% (10 / (10 + 30)) 的 CPU 资源,而 g-b 可获得 75% 的 CPU 资源。如果系统只有一个 Workload Group 正在运行,则不管其 cpu_share 的值为多少,它都可获取全部的 CPU 资源 。 |
| memory_limit | 浮点 | -1 | (0%, 100%] | 可选,开启内存硬限时代表当前 Workload Group 最大可用内存百分比,默认值代表不限制内存。所有 Workload Group 的 memory_limit 累加值不可以超过 100%,通常与 enable_memory_overcommit 属性配合使用。如果一个机器的内存为 64G,Workload Group 的 memory_limit配置为50%,那么该 group 的实际物理内存=64G * 90% * 50%= 28.8G,这里的90%是 BE 进程可用内存配置的默认值。 |
| enable_memory_overcommit | 布尔 | true | true, false | 可选,用于控制当前 Workload Group 的内存限制是硬限还是软限,默认为 true。如果设置为 false,则该 workload group 为内存硬隔离,系统检测到 workload group 内存使用超出限制后将立即 cancel 组内内存占用最大的若干个任务,以释放超出的内存;如果设置为 true,则该 Workload Group 为内存软隔离,如果系统有空闲内存资源则该 Workload Group 在超出 memory_limit 的限制后可继续使用系统内存,在系统总内存紧张时会 cancel 组内内存占用最大的若干个任务,释放部分超出的内存以缓解系统内存压力。建议所有 workload group 的 memory_limit 总和低于 100%,为BE进程中的其他组件保留一些内存。 |
| cpu_hard_limit | 整型 | -1 | [1%, 100%] | 可选,CPU 硬限制模式下生效,Workload Group 最大可用 CPU 百分比,不管当前机器的 CPU 资源是否被用满,Workload Group 的最大 CPU 用量都不能超过 cpu_hard_limit,所有 Workload Group 的 cpu_hard_limit 累加值不能超过 100%。2.1 版本新增属性,2.0版本不支持该功能。 |
| max_concurrency | 整型 | 2147483647 | [0, 2147483647] | 可选,最大查询并发数,默认值为整型最大值,也就是不做并发的限制。运行中的查询数量达到最大并发时,新来的查询会进入排队的逻辑。 |
| max_queue_size | 整型 | 0 | [0, 2147483647] | 可选,查询排队队列的长度,当排队队列已满时,新来的查询会被拒绝。默认值为 0,含义是不排队。当排队队列已满时,新来的查询会直接失败。 |
| queue_timeout | 整型 | 0 | [0, 2147483647] | 可选,查询在排队队列中的最大等待时间,单位为毫秒。如果查询在队列中的排队时间超过这个值,那么就会直接抛出异常给客户端。默认值为 0,含义是不排队,查询进入队列后立即返回失败。 |
| scan_thread_num | 整型 | -1 | [1, 2147483647] | 可选,当前 workload group 用于 scan 的线程个数。当该属性为 -1,含义是不生效,此时在BE上的实际取值为 BE 配置中的doris_scanner_thread_pool_thread_num。 |
| max_remote_scan_thread_num | 整型 | -1 | [1, 2147483647] | 可选,读外部数据源的scan线程池的最大线程数。当该属性为-1时,实际的线程数由BE自行决定,通常和核数相关。 |
| min_remote_scan_thread_num | 整型 | -1 | [1, 2147483647] | 可选,读外部数据源的scan线程池的最小线程数。当该属性为-1时,实际的线程数由BE自行决定,通常和核数相关。 |
| tag | 字符串 | 空 | - | 为Workload Group指定分组标签,相同标签的Workload Group资源累加值不能超过100%;如果期望指定多个值,可以使用英文逗号分隔。 |
| read_bytes_per_second | 整型 | -1 | [1, 9223372036854775807] | 可选,含义为读Doris内表时的最大IO吞吐,默认值为-1,也就是不限制IO带宽。需要注意的是这个值并不绑定磁盘,而是绑定文件夹。比如为Doris配置了2个文件夹用于存放内表数据,那么每个文件夹的最大读IO不会超过该值,如果这2个文件夹都配置到同一块盘上,最大吞吐控制就会变成2倍的read_bytes_per_second。落盘的文件目录也受该值的约束。 |
| remote_read_bytes_per_second | 整型 | -1 | [1, 9223372036854775807] | 可选,含义为读Doris外表时的最大IO吞吐,默认值为-1,也就是不限制IO带宽。 |
-
目前暂不支持 CPU 的软限和硬限的同时使用,一个集群某一时刻只能是软限或者硬限,下文中会描述切换方法。
-
所有属性均为可选,但是在创建 Workload Group 时需要指定至少一个属性。
-
需要注意 CGroup v1 CGroup v2 版本 CPU 软限默认值是有区别的, CGroup v1 的 CPU 软限默认值为1024,取值范围为2到262144。而 CGroup v2 的 CPU 软限默认值为100,取值范围是1到10000。 如果软限填了一个超出范围的值,这会导致 CPU 软限在BE修改失败。如果在 CGroup v1 的环境上如果按照CGroup v2的默认值100设置,这可能导致这个workload group的优先级在该机器上是最低的。
为用户设置Workload Group
在把用户绑定到某个Workload Group之前,需要先确定该用户是否具有某个 Workload Group 的权限。 可以使用这个用户查看 information_schema.workload_groups 系统表,返回的结果就是当前用户有权限使用的Workload Group。 下面的查询结果代表当前用户可以使用 g1 与 normal Workload Group:
SELECT name FROM information_schema.workload_groups;
+--------+
| name |
+--------+
| normal |
| g1 |
+--------+
如果无法看到 g1 Workload Group,可以使用ADMIN账户执行 GRANT 语句为用户授权。例如:
"GRANT USAGE_PRIV ON WORKLOAD GROUP 'g1' TO 'user_1'@'%';"
这个语句的含义是把名为 g1 的 Workload Group的使用权限授予给名为 user_1 的账户。 更多授权操作可以参考grant 语句。
两种绑定方式
- 通过设置 user property 将 user 默认绑定到 workload group,默认为
normal,需要注意的这里的value不能填空,否则语句会执行失败。
set property 'default_workload_group' = 'g1';
执行完该语句后,当前用户的查询将默认使用'g1'。
- 通过 session 变量指定 workload group, 默认为空:
set workload_group = 'g1';
当同时使用了两种方式时为用户指定了Workload Group,session 变量的优先级要高于 user property 。
查看Workload Group
- 通过show语句查看
show workload groups;
可以参考SHOW-WORKLOAD-GROUPS。
- 通过系统表查看
mysql [information_schema]>select * from information_schema.workload_groups where name='g1';
+-------+------+-----------+--------------+--------------------------+-----------------+----------------+---------------+----------------+-----------------+----------------------------+----------------------------+----------------------+-----------------------+------+-----------------------+------------------------------+
| ID | NAME | CPU_SHARE | MEMORY_LIMIT | ENABLE_MEMORY_OVERCOMMIT | MAX_CONCURRENCY | MAX_QUEUE_SIZE | QUEUE_TIMEOUT | CPU_HARD_LIMIT | SCAN_THREAD_NUM | MAX_REMOTE_SCAN_THREAD_NUM | MIN_REMOTE_SCAN_THREAD_NUM | MEMORY_LOW_WATERMARK | MEMORY_HIGH_WATERMARK | TAG | READ_BYTES_PER_SECOND | REMOTE_READ_BYTES_PER_SECOND |
+-------+------+-----------+--------------+--------------------------+-----------------+----------------+---------------+----------------+-----------------+----------------------------+----------------------------+----------------------+-----------------------+------+-----------------------+------------------------------+
| 14009 | g1 | 1024 | -1 | true | 2147483647 | 0 | 0 | -1 | -1 | -1 | -1 | 50% | 80% | | -1 | -1 |
+-------+------+-----------+--------------+--------------------------+-----------------+----------------+---------------+----------------+-----------------+----------------------------+----------------------------+----------------------+-----------------------+------+-----------------------+------------------------------+
1 row in set (0.05 sec)
修改Workload Group
mysql [information_schema]>alter workload group g1 properties('cpu_share'='2048');
Query OK, 0 rows affected (0.00 sec
mysql [information_schema]>select cpu_share from information_schema.workload_groups where name='g1';
+-----------+
| cpu_share |
+-----------+
| 2048 |
+-----------+
1 row in set (0.02 sec)
可以参考:ALTER-WORKLOAD-GROUP。
删除Workload Group
mysql [information_schema]>drop workload group g1;
Query OK, 0 rows affected (0.01 sec)
可以参考:DROP-WORKLOAD-GROUP。
CPU 软硬限模式切换的说明
目前 Doris 暂不支持同时运行 CPU 的软限和硬限,一个 Doris 集群在任意时刻只能是 CPU 软限或者 CPU 硬限。 用户可以在两种模式之间进行切换,切换方法如下:
1 假如当前的集群配置是默认的 CPU 软限,期望改成 CPU 的硬限,需要把 Workload Group 的 cpu_hard_limit 参数修改成一个有效的值
alter workload group test_group properties ( 'cpu_hard_limit'='20%' );
集群中所有的Workload Group都需要修改,所有 Workload Group 的 cpu_hard_limit 的累加值不能超过 100% 。
由于 CPU 的硬限无法给出一个有效的默认值,因此如果只打开开关但是不修改属性,那么 CPU 的硬限也无法生效。
2 在所有 FE 中打开 CPU 硬限的开关
1 修改磁盘上fe.conf的配置
experimental_enable_cpu_hard_limit = true
2 修改内存中的配置
ADMIN SET FRONTEND CONFIG ("enable_cpu_hard_limit" = "true");
如果用户期望从 CPU 的硬限切换回 CPU 的软限,需要在所有 FE 修改 enable_cpu_hard_limit 的值为 false 即可。 CPU 软限的属性 cpu_share 默认会填充一个有效值 1024(如果之前未指定 cpu_share 的值),用户可以根据 group 的优先级对 cpu_share 的值进行重新调整。
效果测试
内存硬限
Adhoc 类查询通常输入的 SQL 不确定,使用的内存资源也不确定,因此存在少数查询占用很大内存的风险。 可以对这类负载可以划分到独立的分组,通过 Workload Group 对内存的硬限的功能,避免突发性的大查询占满所有内存,导致其他查询没有可用内存或者 OOM。 当这个 Workload Group 的内存使用超过配置的硬限值时,会通过杀死查询的方式释放内存,避免进程内存被打满。
测试环境
1FE,1BE,BE 配置为 96 核,内存大小为 375G。
测试数据集为 clickbench,测试方法为使用 jmeter 起三并发执行 q29。
测试不开启 Workload Group 的内存硬限
-
查看进程使用内存。ps 命令输出第四列代表进程使用的物理内存的用量,单位为 kb,可以看到当前测试负载下,进程的内存使用为 7.7G 左右。
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 2.0 7896792
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 2.0 7929692
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 2.0 8101232 -
使用 Doris 系统表查看当前 Workload Group 的内存用量,Workload Group 的内存用量为 5.8G 左右。
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+-------------------+
| wg_mem_used_mb |
+-------------------+
| 5797.524360656738 |
+-------------------+
1 row in set (0.01 sec)
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+-------------------+
| wg_mem_used_mb |
+-------------------+
| 5840.246627807617 |
+-------------------+
1 row in set (0.02 sec)
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+-------------------+
| wg_mem_used_mb |
+-------------------+
| 5878.394917488098 |
+-------------------+
1 row in set (0.02 sec)
这里可以看到进程的内存使用通常要远大于一个 Workload Group 的内存用量,即使进程内只有一个 Workload Group 在跑,这是因为 Workload Group 只统计了查询和部分导入的内存,进程内的其他组件比如元数据,各种 Cache 的内存是不计算 Workload Group 内的,也不由 Workload Group 管理。
测试开启 Workload Group 的内存硬限
-
执行 SQL 命令修改内存配置。
alter workload group g2 properties('memory_limit'='0.5%');
alter workload group g2 properties('enable_memory_overcommit'='false'); -
执行同样的测试,查看系统表的内存用量,内存用量为 1.5G 左右。
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+--------------------+
| wg_mem_used_mb |
+--------------------+
| 1575.3877239227295 |
+--------------------+
1 row in set (0.02 sec)
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+------------------+
| wg_mem_used_mb |
+------------------+
| 1668.77405834198 |
+------------------+
1 row in set (0.01 sec)
mysql [information_schema]>select MEMORY_USAGE_BYTES / 1024/ 1024 as wg_mem_used_mb from workload_group_resource_usage where workload_group_id=11201;
+--------------------+
| wg_mem_used_mb |
+--------------------+
| 499.96760272979736 |
+--------------------+
1 row in set (0.01 sec) -
使用 ps 命令查看进程的内存用量,内存用量为 3.8G 左右。
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 1.0 4071364
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 1.0 4059012
[ ~]$ ps -eo pid,comm,%mem,rss | grep 1407481
1407481 doris_be 1.0 4057068 -
同时客户端会观察到大量由于内存不足导致的查询失败。
1724074250162,14126,1c_sql,HY000 1105,"java.sql.SQLException: errCode = 2, detailMessage = (127.0.0.1)[MEM_LIMIT_EXCEEDED]GC wg for hard limit, wg id:11201, name:g2, used:1.71 GB, limit:1.69 GB, backend:10.16.10.8. cancel top memory used tracker <Query#Id=4a0689936c444ac8-a0d01a50b944f6e7> consumption 1.71 GB. details:process memory used 3.01 GB exceed soft limit 304.41 GB or sys available memory 101.16 GB less than warning water mark 12.80 GB., Execute again after enough memory, details see be.INFO.",并发 1-3,text,false,,444,0,3,3,null,0,0,0
这个报错信息中可以看到,Workload Group 使用了 1.7G 的内存,但是 Workload Group 的限制是 1.69G,这里的计算方式是这样的 1.69G = 物理机内存 (375) * mem_limit(be.conf 中的值,默认为 0.9) * 0.5%(Workload Group 的配置) 也就是说,Workload Group 中配置的内存百分比是基于 Doris 进程可用内存再次进行计算的。
使用建议
如上文测试,硬限可以控制 Workload Group 的内存使用,但却是通过杀死查询的方式释放内存,这对用户来说体验会非常不友好,极端情况下可能会导致所有查询都失败。 因此在生产环境中推荐内存硬限配合查询排队的功能一起使用,可以在限制内存使用的同时保证查询的成功率。
CPU 硬限
Doris 的负载大体可以分为三类:
- 核心报表查询,通常给公司高层查看报表使用,负载不一定很高,但是对可用性要求较高,这类查询可以划分到一个分组,配置较高优先级的软限,保证 CPU 资源不够时可以获得更多的 CPU 资源。
- Adhoc 类查询,这类查询通常偏探索分析,SQL 比较随机,具体的资源用量也比较未知,优先级通常不高。因此可以使用 CPU 硬限进行管理,并配置较低的值,避免占用过多 CPU 资源降低集群可用性。
- ETL 类查询,这类查询的 SQL 比较固定,资源用量通常也比较稳定,偶尔会出现上游数据量增长导致资源用量暴涨的情况,因此可以使用 CPU 硬限进行配置。
不同的负载对 CPU 的消耗不一样,用户对响应延时的需求也不一样。当 BE 的 CPU 被用的很满时,可用性会变差,响应延时会变高。比如可能一个 Adhoc 的分析类查询把整个集群的 CPU 打满,导致核心报表的延时变大,影响到了 SLA。所以需要 CPU 隔离机制来对不同的业务进行隔离,保障集群的可用性和 SLA。 Workload Group 支持 CPU 的软限和硬限,目前比较推荐在线上环境把 Workload Group 配置成硬限。原因是 CPU 的软限通常在 CPU 被打满时才能体现出优先级的作用,但是在 CPU 被用满时,Doris 的内部组件(例如 rpc 组件)以及操作系统可用的 CPU 会减少,此时集群整体的可用性是下降比较严重的,因此生产环境通常需要避免 CPU 资源被打满的情况,当然其他资源也一样,内存资源同理。
测试环境
1FE,1BE,96 核机器。 数据集为 clickbench,测试 sql 为 q29。
发起测试
-
使用 jmeter 发起 3 并发查询,把 BE 进程的 CPU 使用压到比较高的使用率,这里测试的机器是 96 核,使用 top 命令看到 BE 进程 CPU 使用率为 7600% 的含义是该进程目前使用中的核数是 76 个。

-
修改使用中的 Workload Group 的 CPU 硬限为 10%。
alter workload group g2 properties('cpu_hard_limit'='10%'); -
集群开启硬限模式,此时集群中所有 Group 都会切换为硬限。
ADMIN SET FRONTEND CONFIG ("enable_cpu_hard_limit" = "true"); -
重新压测查询负载,可以看到当前进程只能使用 9 到 10 个核,占总核数的 10% 左右。

需要注意的是,这里的测试最好使用查询负载会比较能体现出效果,因为如果是高吞吐导入的话,可能会触发 Compaction,使得实际观测的值要比 Workload Group 配置的值大。而 Compaction 的负载目前是没有归入 Workload Group 的管理的。
-
除了使用 Linux 的系统命令外,还可以通过使用 Doris 的系统表观察 Group 目前的 CPU 使用为 10% 左右。
mysql [information_schema]>select CPU_USAGE_PERCENT from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+-------------------+
| CPU_USAGE_PERCENT |
+-------------------+
| 9.57 |
+-------------------+
1 row in set (0.02 sec)
注意事项
- 在实际配置的时候,所有 Group 的 CPU 累加值最好不要正好等于 100%,这主要是为了保证低延迟场景的可用性。因为需要让出一部分资源给其他组件使用。当然如果对延迟不是很敏感的场景,期望最高的资源利用率,那么可以考虑所有 Group 的 CPU 累加值配置等于 100%。
- 目前 FE 向 BE 同步 Workload Group 元数据的时间间隔为 30 秒,因此对于 Workload Group 的变更最大需要等待 30 秒才能生效。
本地IO 硬限
OLAP 系统在做 ETL 或者大的 Adhoc 查询时,需要读取大量的数据,Doris 为了加速数据分析过程,内部会使用多线程并行的方式对多个磁盘文件扫描,会产生巨大的磁盘 IO,就会对其他的查询(比如报表分析)产生影响。 可以通过 Workload Group 对离线的 ETL 数据处理和在线的报表查询做分组,限制离线数据处理 IO 带宽的方式,降低它对在线报表分析的影响。
测试环境
1FE,1BE, 配置为 96 核。
测试数据集为 clickbench。
不开启 IO 硬限测试
-
关闭缓存。
// 清空操作系统缓存
sync; echo 3 > /proc/sys/vm/drop_caches
// 禁用 BE 的 page cache
disable_storage_page_cache = true -
对 clickbench 的表执行全表扫描,执行单并发查询即可。
set dry_run_query = true;
select * from hits.hits; -
通过 Doris 的内表查看当前 Group 的最大吞吐为 3GB 每秒。
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 1146.6208400726318 |
+--------------------+
1 row in set (0.03 sec)
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 3496.2762966156006 |
+--------------------+
1 row in set (0.04 sec)
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 2192.7690029144287 |
+--------------------+
1 row in set (0.02 sec) -
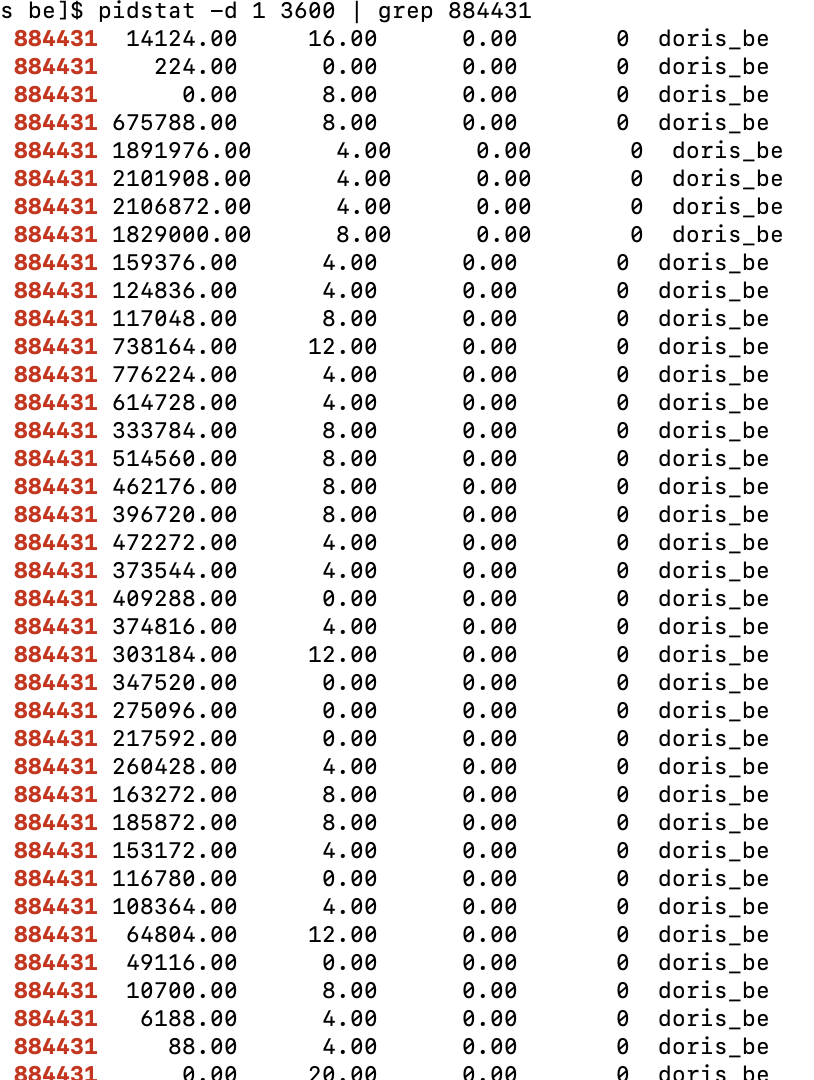
使用 pidstat 命令查看进程 IO,图中第一列是进程 id,第二列是读 IO 的吞吐(单位是 kb/s)。可以看到不限制 IO 时,最大吞吐为 2G 每秒。
开启 IO 硬限后测试
-
关闭缓存。
// 清空操作系统缓存
sync; echo 3 > /proc/sys/vm/drop_caches
// 禁用 BE 的 page cache
disable_storage_page_cache = true -
修改 Workload Group 的配置,限制每秒最大吞吐为 100M。
// 限制当前 Group 的读吞吐为每秒 100M
alter workload group g2 properties('read_bytes_per_second'='104857600'); -
使用 Doris 系统表查看 Workload Group 的最大 IO 吞吐为每秒 98M。
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 97.94296646118164 |
+--------------------+
1 row in set (0.03 sec)
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 98.37584781646729 |
+--------------------+
1 row in set (0.04 sec)
mysql [information_schema]>select LOCAL_SCAN_BYTES_PER_SECOND / 1024 / 1024 as mb_per_sec from workload_group_resource_usage where WORKLOAD_GROUP_ID=11201;
+--------------------+
| mb_per_sec |
+--------------------+
| 98.06641292572021 |
+--------------------+
1 row in set (0.02 sec) -
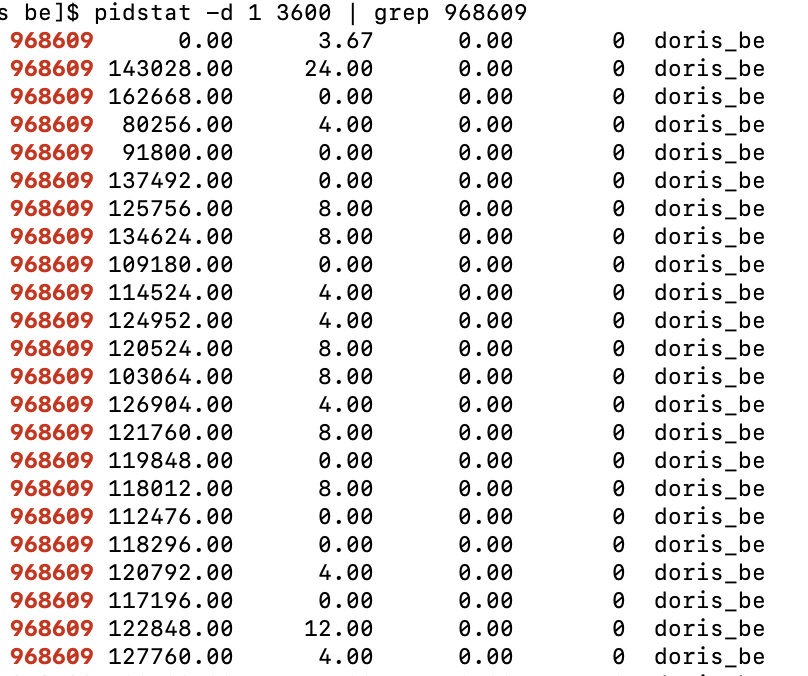
使用 pid 工具查看进程最大 IO 吞吐为每秒 131M。
注意事项
-
系统表中的 LOCAL_SCAN_BYTES_PER_SECOND 字段代表的是当前 Workload Group 在进程粒度的统计汇总值,比如配置了 12 个文件路径,那么 LOCAL_SCAN_BYTES_PER_SECOND 就是这 12 个文件路径 IO 的最大值,如果期望查看每个文件路径分别的 IO 吞吐,可以在 grafana 监控查看明细的值。
-
由于操作系统和 Doris 的 Page Cache 的存在,通过 linux 的 IO 监控脚本看到的 IO 通常要比系统表看到的要小。
远程 IO 硬限
BrokerLoad 和 S3Load 是常用的大批量数据导入方式,用户可以把数据先上传到 HDFS 或者 S3,然后通过 Brokerload 和 S3Load 对数据进行并行导入。Doris 为了加快导入速度,会使用多线程并行的方式从 HDFS/S3 拉取数据,此时会对 HDFS/S3 产生巨大的压力,会导致 HDFS/S3 上运行的别的作业不稳定。 可以通过 Workload Group 远程 IO 的限制功能来限制导入过程中对 HDFS/S3 的带宽,降低对其他业务的影响。
测试环境
1FE,1BE 部署在同一台机器,配置为 16 核 64G 内存。测试数据为 clickbench 数据集,测试前需要把数据集上传到 S3 上。考虑到上传时间的问题,我们只取其中的 1 千万行数据上传,然后使用 tvf 的功能查询 s3 的数据。
上传成功后可以使用命令查看 Schema 信息。
```sql
// 查看schema
DESC FUNCTION s3 (
"URI" = "https://bucketname/1kw.tsv",
"s3.access_key"= "ak",
"s3.secret_key" = "sk",
"format" = "csv",
"use_path_style"="true"
);
```
测试不限制远程读的 IO
-
发起单并发测试,全表扫描 clickbench 表。
// 设置只 scan 数据,不返回结果
set dry_run_query = true;
// 使用 tvf 查询 s3 的数据
SELECT * FROM s3(
"URI" = "https://bucketname/1kw.tsv",
"s3.access_key"= "ak",
"s3.secret_key" = "sk",
"format" = "csv",
"use_path_style"="true"
); -
使用系统表查看此时的远程 IO 吞吐。可以看到这个查询的远程 IO 吞吐为 837M 每秒,需要注意的是,这里的实际 IO 吞吐受环境影响较大,如果 BE 所在的机器连接外部存储的带宽比较低,那么可能实际的吞吐会小。
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 837 |
+---------+
1 row in set (0.104 sec)
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 867 |
+---------+
1 row in set (0.070 sec)
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 867 |
+---------+
1 row in set (0.186 sec) -
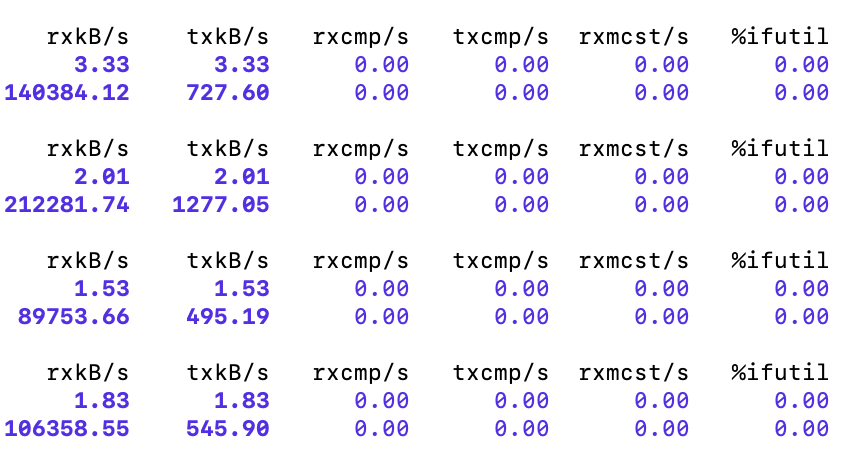
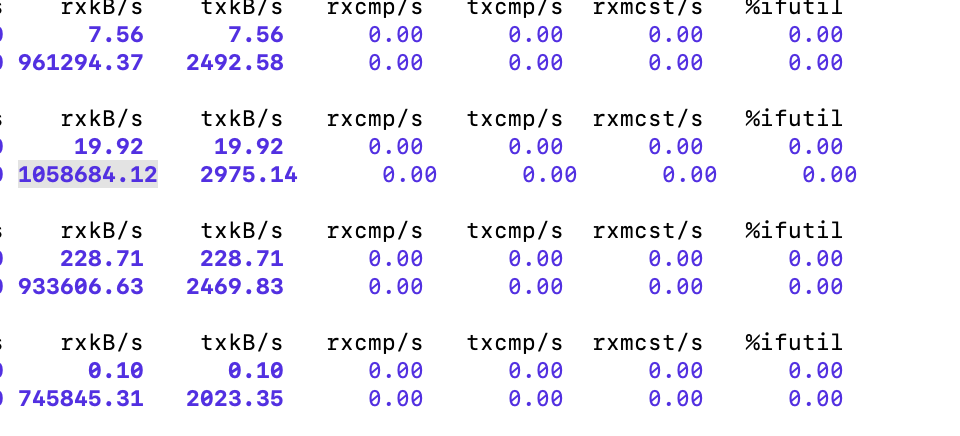
使用 sar(sar -n DEV 1 3600) 命令查看机器的网络带宽,可以看到机器级别最大网络带宽为 1033M 每秒。 输出的第一列为当前机器某个网卡每秒接收的字节数,单位为 KB 每秒。
测试限制远程读的 IO
-
修改 Workload Group 的配置,限制远程读的 IO 吞吐为 100M 每秒。
alter workload group normal properties('remote_read_bytes_per_second'='104857600'); -
发起单并发扫全表的查询。
// 设置只 scan 数据,不返回结果
set dry_run_query = true;
// 使用 tvf 查询 s3 的数据
SELECT * FROM s3(
"URI" = "https://bucketname/1kw.tsv",
"s3.access_key"= "ak",
"s3.secret_key" = "sk",
"format" = "csv",
"use_path_style"="true"
); -
使用系统表查看此时的远程读 IO 吞吐,此时的 IO 吞吐在 100M 左右,会有一定的波动,这个波动是受目前算法设计的影响,通常会有一个高峰,但不会持续很长时间,属于正常情况。
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 56 |
+---------+
1 row in set (0.010 sec)
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 131 |
+---------+
1 row in set (0.009 sec)
MySQL [(none)]> select cast(REMOTE_SCAN_BYTES_PER_SECOND/1024/1024 as int) as read_mb from information_schema.workload_group_resource_usage;
+---------+
| read_mb |
+---------+
| 111 |
+---------+
1 row in set (0.009 sec) -
使用 sar 命令(sar -n DEV 1 3600)查看目前的网卡接收流量,第一列为每秒接收的数据量,可以看到最大值变成了 207M 每秒,说明读 IO 的限制是生效的,但是由于 sar 命令看到的是机器级别的流量,因此要比 Doris 统计到的会大一些。