Release 1.2.0
亲爱的社区小伙伴们,再一次经历数月的等候后,我们很高兴地宣布,Apache Doris 于 2022 年 12 月 7 日迎来 1.2.0 Release 版本的正式发布!有近 118 位 Contributor 为 Apache Doris 提交了超 2400 项优化和修复,感谢每一位让 Apache Doris 更好的你!
自从社区正式确立 LTS 版本管理机制后,在 1.1.x 系列版本中不再合入大的功能,仅提供问题修复和稳定性改进,力求满足更多社区用户在稳定性方面的高要求。而在综合考虑版本迭代节奏和用户需求后,我们决定将众多新特性在 1.2 版本中发布,这无疑承载了众多社区用户和开发者的深切期盼,同时这也是一场厚积而薄发后的全面进化!
在 1.2 版本中,我们实现了全面的向量化、实现多场景查询性能 3-11 倍的提升,在 Unique Key 模型上实现了 Merge-on-Write 的数据更新模式、数据高频更新时查询性能提升达 3-6 倍,增加了 Multi-Catalog 多源数据目录、提供了无缝接入 Hive、ES、Hudi、Iceberg 等外部数据源的能力,引入了 Light Schema Change 轻量表结构变更、实现毫秒级的 Schema Change 操作并可以借助 Flink CDC 自动同步上游数据库的 DML 和 DDL 操作,以 JDBC 外部表替换了过去的 ODBC 外部表,支持了 Java UDF 和 Romote UDF 以及 Array 数组类型和 JSONB 类型,修复了诸多之前版本的性能和稳定性问题,推荐大家下载和使用!
下载安装
GitHub下载:https://github.com/apache/doris/releases
官网下载页:https://doris.apache.org/download
源码地址:https://github.com/apache/doris/releases/tag/1.2.0-rc04
下载说明:
由于 Apache 服务器文件大小限制,官网下载页的 1.2.0 版本的二进制程序分为三个包:
apache-doris-fe
apache-doris-be
apache-doris-java-udf-jar-with-dependencies
其中新增的 apache-doris-java-udf-jar-with-dependencies 包用于支持 1.2.0 版本中的 JDBC 外表和 JAVA UDF 。下载后,需要将其中的 java-udf-jar-with-dependencies.jar 文件放到 be/lib 目录下,方可启动 BE,否则无法启动成功。
部署说明:
从历史版本升级到 1.2.0 版本,需完整更新 fe、be 下的 bin 和 lib 目录。
其他升级注意事项,请完整阅读本发版通告最后一节“升级注意事项”以及安装部署文档 https://doris.apache.org/zh-CN/docs/dev/install/install-deploy 和集群升级文档 https://doris.apache.org/zh-CN/docs/dev/admin-manual/cluster-management/upgrade
重要更新
1. 全面向量化支持,性能大幅提升
在 Apache Doris 1.2.0 版本中,系统所有模块都实现了向量化,包括数据导入、Schema Change、Compaction、数据导出、UDF 等。新版向量化执行引擎具备了完整替换原有非向量化引擎的能力,后续我们也将考虑在未来版本中去除原有非向量化引擎的代码。
与此同时,在全面向量化的基础上,我们对数据扫描、谓词计算、Aggregation 算子、HashJoin 算子、算子之间 Shuffle 效率等进行了全链路的优化,使得查询性能有了大幅提升。
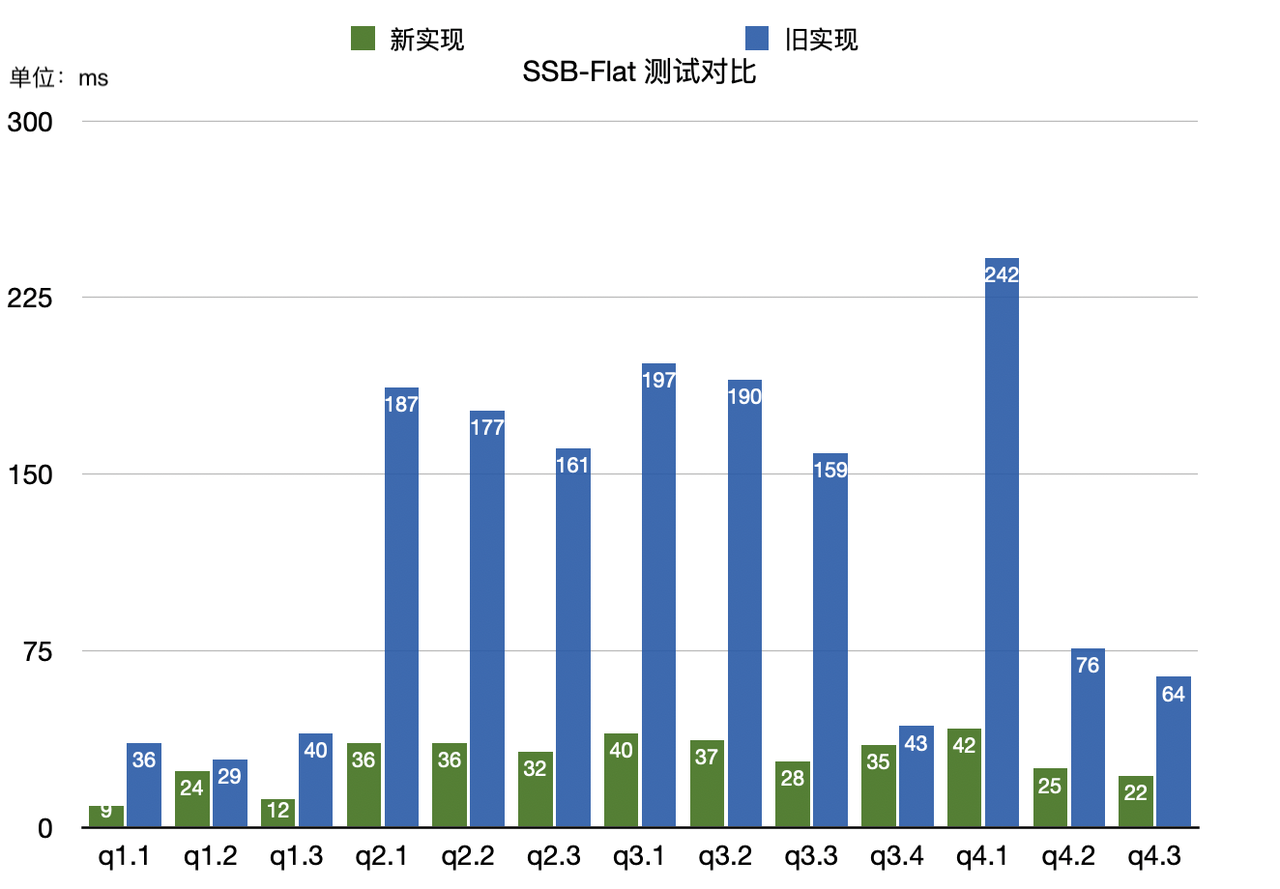
我们对 Apache Doris 1.2.0 新版本进行了多个标准测试集的测试,同时选择了 1.1.3 版本和 0.15.0 版本作为对比参照项。经测,1.2.0 在 SSB-Flat 宽表场景上相对 1.1.3 版本整体性能提升了近 4 倍、相对于 0.15.0 版本性能提升了近 10 倍,在 TPC-H 多表关联场景上较 1.1.3 版本上有近 3 倍的提升、较 0.15.0 版本性能至少提升了 11 倍。
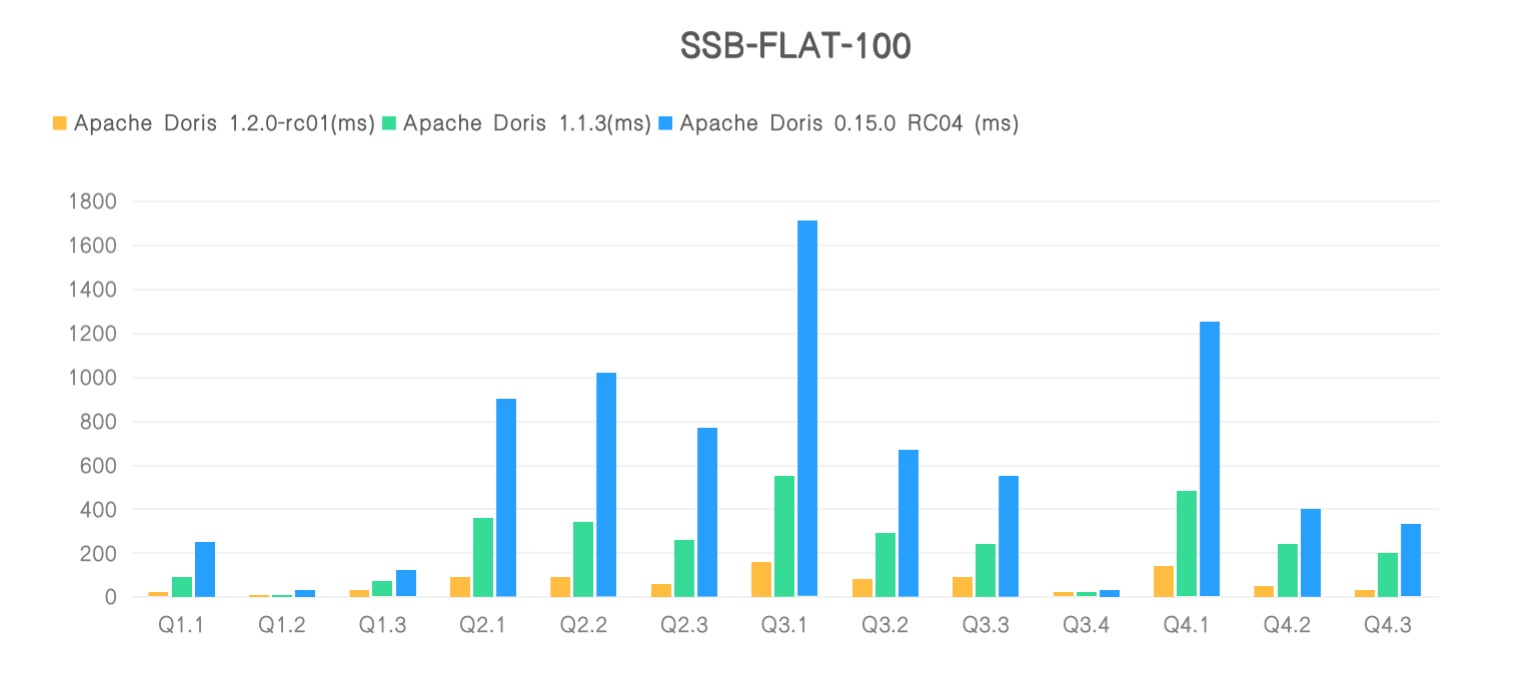
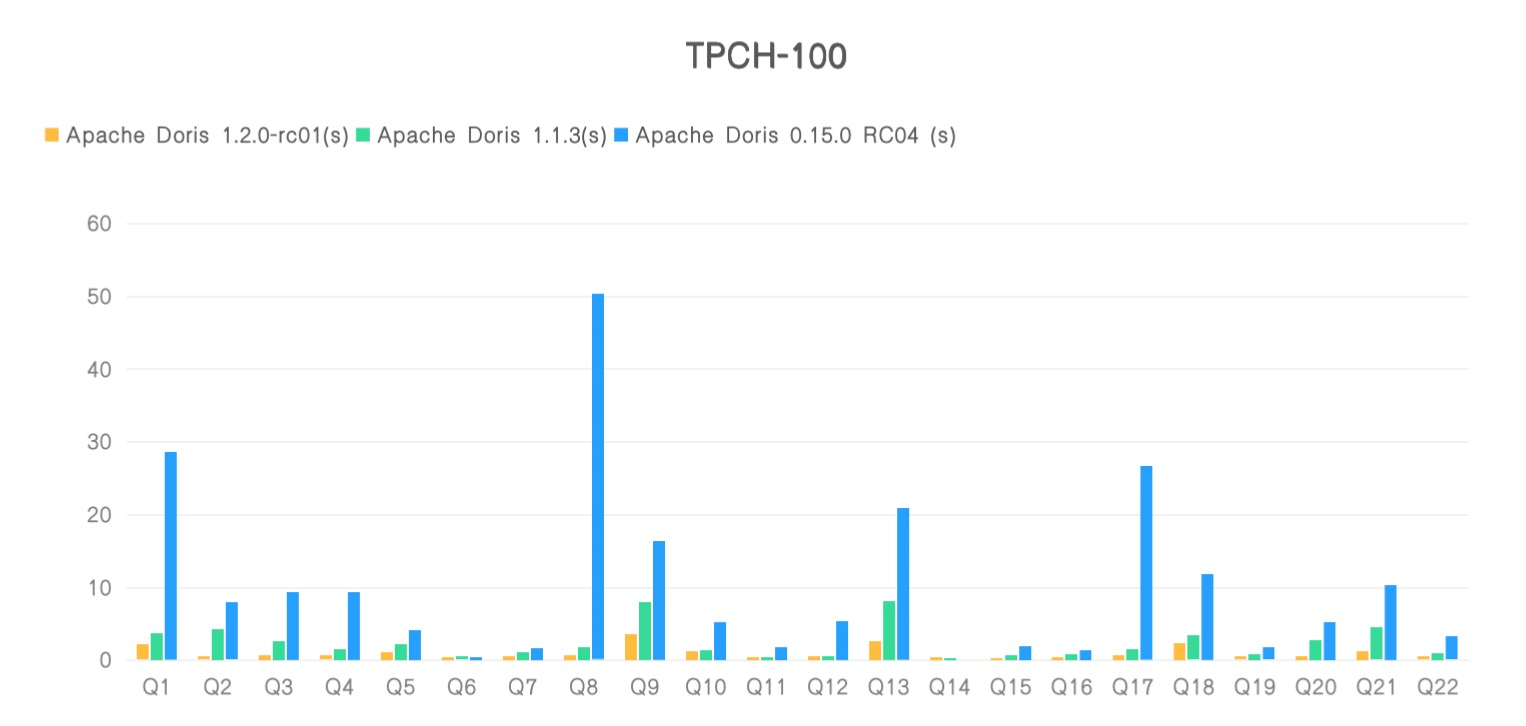
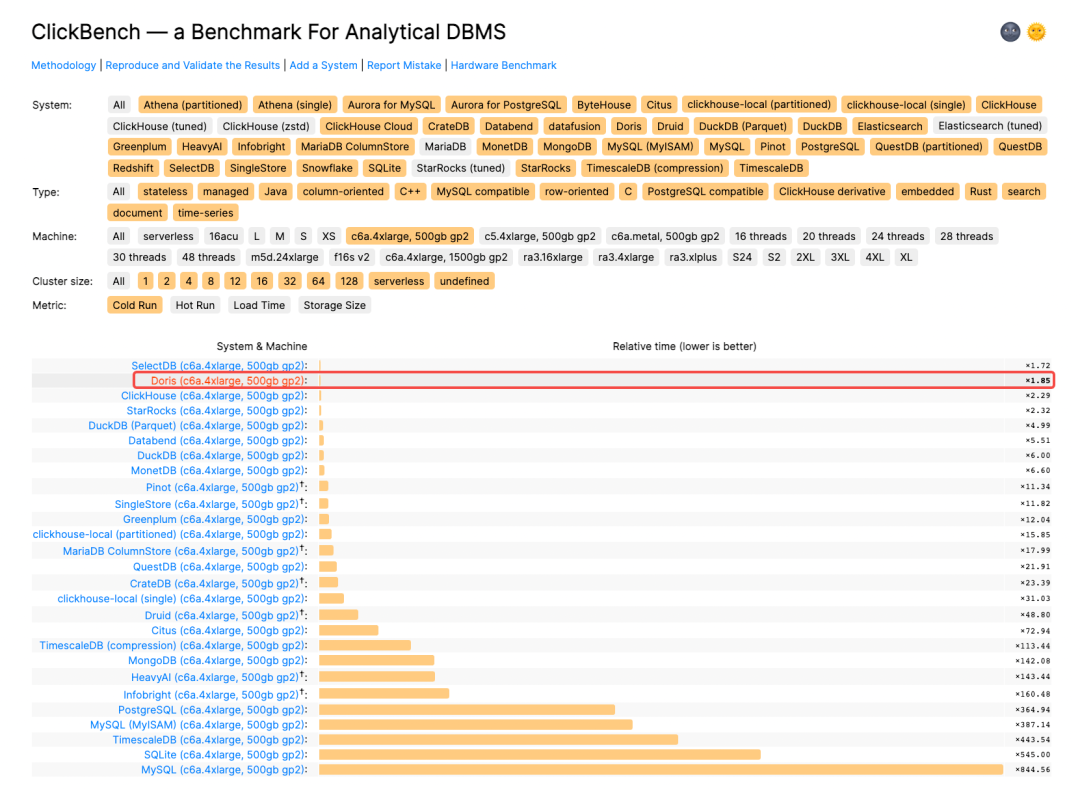
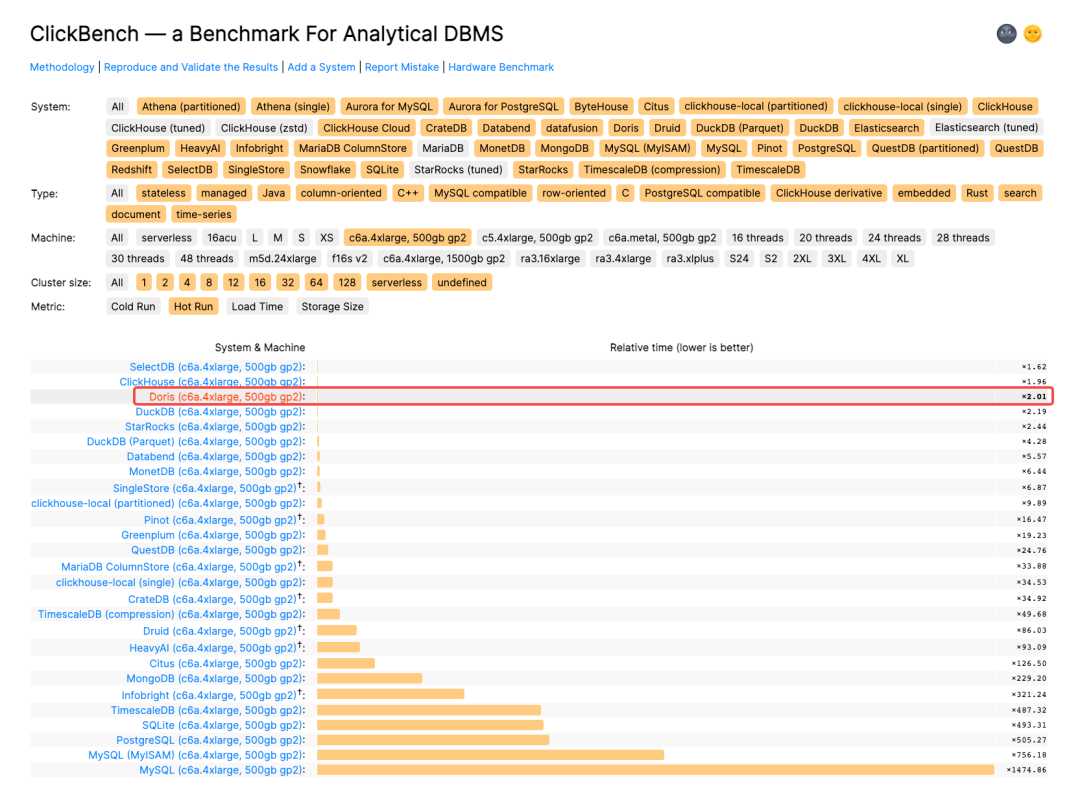
同时,我们将 1.2.0 版本的测试数据提交到了全球知名的数据库测试排行榜 ClickBench,在最新的排行榜中,Apache Doris 1.2.0 新版本取得了通用机型(c6a.4xlarge, 500gb gp2)下查询性能 Cold Run 第二和 Hot Run 第三的醒目成绩,共有 8 个 SQL 刷新榜单最佳成绩、成为新的性能标杆。导入性能方面,1.2.0 新版本数据写入效率在同机型所有产品中位列第一,压缩前 70G 数据写入仅耗时 415s、单节点写入速度超过 170 MB/s,在实现极致查询性能的同时也保证了高效的写入效率!
2. 在 Unique Key 模型上实现了 Merge-on-Write 的数据更新模式
在过去版本中, Apache Doris 主要是通过 Unique Key 数据模型来实现数据实时更新的。但由于采用的是 Merge-on-Read 的实现方式,查询存在着效率瓶颈,有大量非必要的 CPU 计算资源消耗和 IO 开销,且可能将出现查询性能抖动等问题。
在 1.2.0 版本中,我们在原有的 Unique Key 数据模型上,增加了 Merge-on-Write 的数据更新模式。该模式在数据写入时即对需要删除或更新的数据进行标记,始终保证有效的主键只出现在一个文件中(即在写入的时候保证了主键的唯一性),不需要在读取的时候通过归并排序来对主键进行去重,这对于高频写入的场景来说,大大减少了查询执行时的额外消耗。此外还能够支持谓词下推,并能够很好利用 Doris 丰富的索引,在数据 IO 层面就能够进行充分的数据裁剪,大大减少数据的读取量和计算量,因此在很多场景的查询中都有非常明显的性能提升。
在比较有代表性的 SSB-Flat 数据集上,通过模拟多个持续导入场景,新版本的大部分查询取得了 3-6 倍的性能提升。
使用场景:所有对主键唯一性有需求,需要频繁进行实时 Upsert 更新的用户建议打开。
使用说明:作为新的 Feature 默认关闭,用户可以通过在建表时添加下面的 Property 来开启:
“enable_unique_key_merge_on_write” = “true”
另外新版本 Merge-on-Write 数据更新模式与旧版本 Merge-on-Read 实现方式存在差异,因此已经创建的 Unique Key 表无法直接通过 Alter Table 添加 Property 来支持,只能在新建表的时候指定。如果用户需要将旧表转换到新表,可以使用 insert into new_table select * from old_table 的方式来实现。
3. Multi Catalog 多源数据目录
Multi-Catalog 多源数据目录功能的目标在于能够帮助用户更方便对接外部数据目录,以增强 Apache Doris 的数据湖分析和联邦数据查询能力。
在过去版本中,当我们需要对接外部数据源时,只能在 Database 或 Table 层级对接。当外部数据目录 Schema 发生变化、或者外部数据目录的 Database 或 Table 非常多时,需要用户手工进行一一映射,维护量非常大。1.2.0 版本新增的多源数据目录功能为 Apache Doris 提供了快速接入外部数据源进行访问的能力,用户可以通过 CREATE CATALOG 命令连接到外部数据源,Doris 会自动映射外部数据源的库、表信息。之后,用户就可以像访问普通表一样,对这些外部数据源中的数据进行访问,避免了之前用户需要对每张表手动建立外表映射的复杂操作。
目前能支持以下数据源:
Hive Metastore:可以访问包括 Hive、Iceberg、Hudi 在内的数据表,也可对接兼容 Hive Metastore 的数据源,如阿里云的 DataLake Formation,同时支持 HDFS 和对象存储上的数据访问。
Elasticsearch:访问 ES 数据源。
JDBC:支持通过 JDBC 访问 MySQL 数据源。
注:相应的权限层级也会自动变更,详见“升级注意事项”部分
文档:https://doris.apache.org/zh-CN/docs/dev/lakehouse/multi-catalog
4. 轻量表结构变更 Light Schema Change
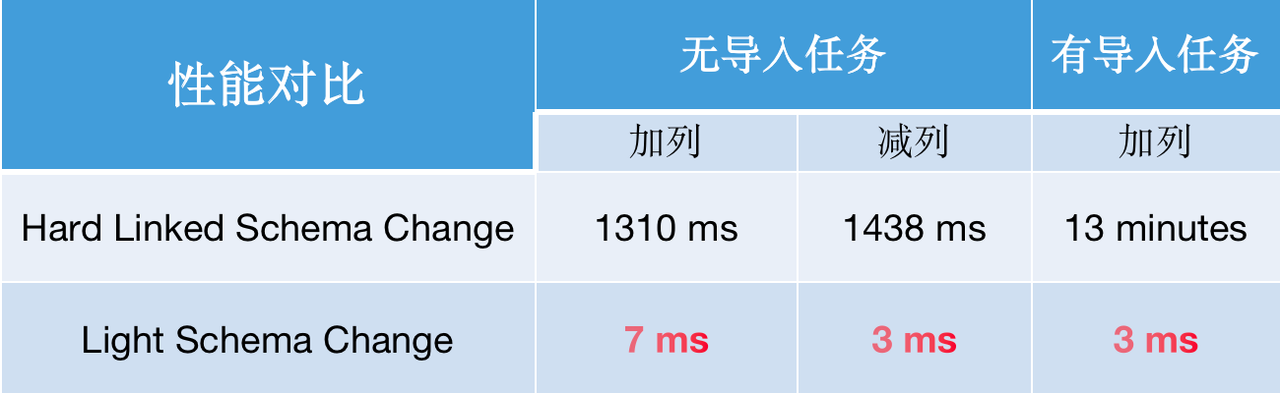
在过去版本中,Schema Change 是一项相对消耗比较大的工作,需要对数据文件进行修改,在集群规模和表数据量较大时执行效率会明显降低。同时由于是异步作业,当上游 Schema 发生变更时,需要停止数据同步任务并手动执行 Schema Change,增加开发和运维成本的同时还可能造成消费数据的挤压。
在 1.2.0 新版本中,对数据表的加减列操作,不再需要同步更改数据文件,仅需在 FE 中更新元数据即可,从而实现毫秒级的 Schema Change 操作,且存在导入任务时效率的提升更为显著。与此同时,使得 Apache Doris 在面对上游数据表维度变化时,可以更加快速稳定实现表结构同步,保证系统的高效且平稳运转。如用户可以通过 Flink CDC,可实现上游数据库到 Doris 的 DML 和 DDL 同步,进一步提升了实时数仓数据处理和分析链路的时效性与便捷性。
使用说明:作为新的 Feature 默认关闭,用户可以通过在建表时添加下面的 Property 来开启:
"light_schema_change" = "true"
5. JDBC 外部表
在过去版本中,Apache Doris 提供了 ODBC 外部表的方式来访问 MySQL、Oracle、SQL Server、PostgreSQL 等数据源,但由于 ODBC 驱动版本问题可能造成系统的不稳定。相对于 ODBC,JDBC 接口更为统一且支持数据库众多,因此在 1.2.0 版本中我们实现了 JDBC 外部表以替换原有的 ODBC 外部表。在新版本中,用户可以通过 JDBC 连接支持 JDBC 协议的外部数据源,
当前已适配的数据源包括:
- MySQL
- PostgreSQL
- Oracle
- SQLServer
- ClickHouse
更多数据源的适配已经在规划之中,原则上任何支持 JDBC 协议访问的数据库均能通过 JDBC 外部表的方式来访问。而之前的 ODBC 外部表功能将会在后续的某个版本中移除,还请尽量切换到 JDBC 外表功能。
文档:https://doris.apache.org/zh-CN/docs/dev/lakehouse/multi-catalog/jdbc
6. JAVA UDF
在过去版本中,Apache Doris 提供了 C++ 语言的原生 UDF,便于用户通过自己编写自定义函数来满足特定场景的分析需求。但由于原生 UDF 与 Doris 代码耦合度高、当 UDF 出现错误时可能会影响集群稳定性,且只支持 C++ 语言,对于熟悉 Hive、Spark 等大数据技术栈的用户而言存在较高门槛,因此在 1.2.0 新版本我们增加了 Java 语言的自定义函数,支持通过 Java 编写 UDF/UDAF,方便用户在 Java 生态中使用。同时,通过堆外内存、Zero Copy 等技术,使得跨语言的数据访问效率大幅提升。
文档:https://doris.apache.org/zh-CN/docs/dev/ecosystem/udf/java-user-defined-function
示例:https://github.com/apache/doris/tree/master/samples/doris-demo
7. Remote UDF
远程 UDF 支持通过 RPC 的方式访问远程用户自定义函数服务,从而彻底消除用户编写 UDF 的语言限制,用户可以使用任意编程语言实现自定义函数,完成复杂的数据分析工作。
文档:https://doris.apache.org/zh-CN/docs/ecosystem/udf/remote-user-defined-function
示例:https://github.com/apache/doris/tree/master/samples/doris-demo
8. Array/JSONB 复合数据类型
- Array 类型
支持了数组类型,同时也支持多级嵌套的数组类型。在一些用户画像,标签等场景,可以利用 Array 类型更好的适配业务场景。同时在新版本中,我们也实现了大量数组相关的函数,以更好的支持该数据类型在实际场景中的应用。
文档:https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/ARRAY
相关函数:https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/array-functions/array
- JSONB 类型
支持二进制的 JSON 数据类型 JSONB。该类型提供更紧凑的 JSONB 编码格式,同时提供在编码格式上的数据访问,相比于使用字符串存储的 JSON 数据,有数倍的性能提升。
文档:https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/JSONB
相关函数:https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/json-functions/jsonb_parse
9. DateV2/DatatimeV2 新版日期/日期时间数据类型
支持 DataV2 日期类型和 DatatimeV2 日期时间类型,相较于原有的 Data 和 Datatime 效率更高且支持最多到微秒的时间精度,建议使用新版日期类型。
文档:https://doris.apache.org/zh-CN/docs/1.2/sql-manual/sql-reference/Data-Types/DATETIMEV2
https://doris.apache.org/zh-CN/docs/1.2/sql-manual/sql-reference/Data-Types/DATEV2
影响范围:
- 用户需要在建表时指定 DateV2 和 DatetimeV2,原有表的 Date 以及 Datetime 不受影响。
- Datev2 和 Datetimev2 在与原来的 Date 和 Datetime 做计算时(例如等值连接),原有类型会被cast 成新类型做计算
- Example 参考文档中说明
10. 全新内存管理框架
在 Apache Doris 1.2.0 版本中我们增加了全新的内存跟踪器(Memory Tracker),用以记录 Doris BE 进程内存使用,包括查询、导入、Compaction、Schema Change 等任务生命周期中使用的内存以及各项缓存。通过 Memory Tracker 实现了更加精细的内存监控和控制,大大减少了因内存超限导致的 OOM 问题,使系统稳定性进一步得到提升。
文档:https://doris.apache.org/zh-CN/docs/dev/admin-manual/maint-monitor/memory-management/memory-tracker
11. Table Valued Function 表函数
增加了 Table Valued Function(TVF,表函数),TVF 可以视作一张普通的表,可以出现在 SQL 中所有“表”可以出现的位置,让用户像访问关系表格式数据一样,读取或访问来自 HDFS 或 S3 上的文件内容,
例如使用 S3 TVF 实现对象存储上的数据导入:
insert into tbl select * from s3("s3://bucket/file.*", "ak" = "xx", "sk" = "xxx") where c1 > 2;
或者直接查询 HDFS 上的数据文件:
insert into tbl select * from hdfs("hdfs://bucket/file.*") where c1 > 2;
TVF 可以帮助用户充分利用 SQL 丰富的表达能力,灵活处理各类数据。
文档: https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/table-functions/s3
https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-functions/table-functions/hdfs
更多功能
1. 更便捷的分区创建方式
支持通过 FROM TO 命令创建一个时间范围内的多个分区。
文档搜索“MULTI RANGE”: https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE
示例:
// 根据时间date 创建分区,支持多个批量逻辑和单独创建分区的混合使用
PARTITION BY RANGE(event_day)(
FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR,
FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH,
FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK,
FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY,
PARTITION p_20230114 VALUES [('2023-01-14'), ('2023-01-15'))
)
// 根据时间datetime 创建分区
PARTITION BY RANGE(event_time)(
FROM ("2023-01-03 12") TO ("2023-01-14 22") INTERVAL 1 HOUR
)
2. 列重命名
对于开启了 Light Schema Change 的表,支持对列进行重命名。
3. 更丰富权限管理
- 支持行级权限
可以通过 CREATE ROW POLICY 命令创建行级权限。
支持指定密码强度、过期时间等。
支持在多次失败登录后锁定账户。
4. 导入相关
- CSV 导入支持带 header 的 CSV 文件。
在文档中搜索 csv_with_names:https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/STREAM-LOAD/
- Stream Load 新增
hidden_columns,可以显式指定 delete flag 列和 sequence 列。
在文档中搜索 hidden_columns:https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/STREAM-LOAD
Spark Load 支持 Parquet 和 ORC 文件导入。
支持清理已完成的导入的 Label 文档:https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/CLEAN-LABEL
支持通过状态批量取消导入作业 文档:https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Manipulation-Statements/Load/CANCEL-LOAD
Broker Load 新增支持阿里云 OSS,腾讯 CHDFS 和华为云 OBS。
文档:https://doris.apache.org/zh-CN/docs/dev/advanced/broker
- 支持通过 hive-site.xml 文件配置访问 HDFS。
文档:https://doris.apache.org/zh-CN/docs/dev/admin-manual/config/config-dir
5. 支持通过 SHOW CATALOG RECYCLE BIN 功能查看回收站中的内容。
6. 支持 SELECT * EXCEPT 语法。
文档:https://doris.apache.org/zh-CN/docs/dev/data-table/basic-usage
7. OUTFILE 支持 ORC 格式导出,并且支持多字节分隔符。
8. 支持通过配置修改可保存的 Query Profile 的数量。
文档搜索 FE 配置项:max_query_profile_num
9. DELETE 语句支持 IN 谓词条件。并且支持分区裁剪。
10. 时间列的默认值支持使用 CURRENT_TIMESTAMP
文档中搜索 "CURRENT_TIMESTAMP":https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE
11. 添加两张系统表:backends、rowsets
backends 是 Doris 中内置系统表,存放在 information_schema 数据库下,通过该系统表可以查看当前 Doris 集群中的 BE 节点信息。
rowsets 是 Doris 中内置系统表,存放在 information_schema 数据库下,通过该系统表可以查看 Doris 集群中各个 BE 节点当前 rowsets 情况。
文档:
https://doris.apache.org/zh-CN/docs/dev/admin-manual/system-table/backends
https://doris.apache.org/zh-CN/docs/dev/admin-manual/system-table/rowsets
12. 备份恢复
Restore作业支持
reserve_replica参数,使得恢复后的表的副本数和备份时一致。Restore 作业支持
reserve_dynamic_partition_enable参数,使得恢复后的表保持动态分区开启状态。支持通过内置的 libhdfs 进行备份恢复操作,不再依赖 broker。
13. 支持同机多磁盘之间的数据均衡
文档:
14. Routine Load 支持订阅 Kerberos 认证的 Kafka 服务。
文档中搜索 kerberos:https://doris.apache.org/zh-CN/docs/dev/data-operate/import/import-way/routine-load-manual
15. New built-in-function 新增内置函数
新增以下内置函数:
- cbrt
- sequence_match/sequence_count
- mask/mask_first_n/mask_last_n
- elt
- any/any_value
- group_bitmap_xor
- ntile
- nvl
- uuid
- initcap
- regexp_replace_one/regexp_extract_all
- multi_search_all_positions/multi_match_any
- domain/domain_without_www/protocol
- running_difference
- bitmap_hash64
- murmur_hash3_64
- to_monday
- not_null_or_empty
- window_funnel
- outer combine 以及所有 Array 函数
升级注意事项
FE 元数据版本变更 【重要】
FE Meta Version 由 107 变更为 114,因此从 1.1.x 以及更早版本升级至 1.2.0 版本后,不可回滚到之前版本。 升级过程中,建议通过灰度升级的方式,先升级部分节点并观察业务运行情况,以降低升级风险,若执行非法的回滚操作将可能导致数据丢失与损坏。
行为改变
权限层级变更。
因为引入了 Catalog 层级,所以相应的用户权限层级也会自动变更。规则如下:
- GlobalPrivs 和 ResourcePrivs 保持不变
- 新增 CatalogPrivs 层级。
- 原 DatabasePrivs 层级增加 internal 前缀(表示 internal catalog 中的 db)
- 原 TablePrivs 层级增加 internal 前缀(表示internal catalog中的 tbl)
GroupBy 和 Having 子句中,优先使用列名而不是别名进行匹配。
不再支持创建以 "mv" 开头的列。"mv" 是物化视图中的保留关键词
移除了 order by 语句默认添加的 65535 行的 Limit 限制,并增加 Session 变量
default_order_by_limit可以自定配置这个限制。"Create Table As Select" 生成的表,所有字符串列统一使用 String类型,不再区分 varchar/char/string
audit log 中,移除 db 和 user 名称前的
default_cluster字样。audit log 中增加 sql digest 字段
union 子句总 order by 逻辑变动。新版本中,order by 子句将在 union 执行完成后执行,除非通过括号进行显式的关联。
进行 decommission 操作时,会忽略回收站中的 tablet,确保 decomission 能够完成。
Decimal 的返回结果将按照原始列中声明的精度进行显示 ,或者按照显式指定的 cast 函数中的精度进行展示。
列名的长度限制由 64 变更为 256
FE 配置项变动
- 默认开启
enable_vectorized_load参数。 - 增大了
create_table_timeout值。建表操作的默认超时时间将增大。 - 修改
stream_load_default_timeout_second默认值为 3天。 - 修改
alter_table_timeout_second的默认值为 一个月。 - 增加参数
max_replica_count_when_schema_change用于限制 alter 作业中涉及的 replica数量,默认为100000。 - 添加
disable_iceberg_hudi_table。默认禁用了 iceberg 和 hudi 外表,推荐使用 multi catalog功能。
- 默认开启
BE 配置项变动
- 移除了
disable_stream_load_2pc参数。2PC的stream load可直接使用。 - 修改
tablet_rowset_stale_sweep_time_sec,从1800秒修改为 300 秒。
- 移除了
Session变量变动
- 修改变量
enable_insert_strict默认为 true。这会导致一些之前可以执行,但是插入了非法值的insert操作,不再能够执行。 - 修改变量
enable_local_exchange默认为 true - 默认通过 lz4 压缩进行数据传输,通过变量
fragment_transmission_compression_codec控制 - 增加
skip_storage_engine_merge变量,用于调试 unique 或 agg 模型的数据 文档:https://doris.apache.org/zh-CN/docs/dev/advanced/variables
- 修改变量
BE 启动脚本会通过
/proc/sys/vm/max_map_count检查数值是否大于200W,否则启动失败。移除了 mini load 接口
升级过程中需注意
- 升级准备
- 需替换:lib, bin 目录(start/stop 脚本均有修改)
- BE 也需要配置 JAVA_HOME,已支持 JDBC Table 和 Java UDF。
- fe.conf 中默认 JVM Xmx 参数修改为 8GB。
- 升级过程中可能的错误
- repeat 函数不可使用并报错:
vectorized repeat function cannot be executed,可以在升级前先关闭向量化执行引擎。 - schema change 失败并报错:
desc_tbl is not set. Maybe the FE version is not equal to the BE - 向量化 hash join 不可使用并报错。
vectorized hash join cannot be executed。可以在升级前先关闭向量化执行引擎。
以上错误在完全升级后会恢复正常。
性能影响
- 默认使用 JeMalloc 作为新版本 BE 的内存分配器,替换 TcMalloc 。
JeMalloc 相比 TcMalloc 使用的内存更少、高并发场景性能更高,但在内存充足的性能测试时,TcMalloc 比 JeMalloc 性能高5%-10%,详细测试见: https://github.com/apache/doris/pull/12496
- tablet sink 中的 batch size 修改为至少 8K。
- 默认关闭 Page Cache 和 减少 Chunk Allocator 预留内存大小
Page Cache 和 Chunk Allocator 分别缓存用户数据块和内存预分配,这两个功能会占用一定比例的内存并且不会释放。由于这部分内存占用无法灵活调配,导致在某些场景下可能因这部分内存占用而导致其他任务内存不足,影响系统稳定性和可用性,因此新版本中默认关闭了这两个功能。
但在某些延迟敏感的报表场景下,关闭该功能可能会导致查询延迟增加。如用户担心升级后该功能对业务造成影响,可以通过在 be.conf 中增加以下参数以保持和之前版本行为一致。
disable_storage_page_cache=false
chunk_reserved_bytes_limit=10%
API 变化
BE 的 http api 错误返回信息,由
{"status": "Fail", "msg": "xxx"}变更为更具体的{"status": "Not found", "msg": "Tablet not found. tablet_id=1202"}SHOW CREATE TABLE中, comment的内容由双引号包裹变为单引号包裹支持普通用户通过 http 命令获取 query profile。
文档:https://doris.apache.org/zh-CN/docs/dev/admin-manual/http-actions/fe/manager/query-profile-action
- 优化了 sequence 列的指定方式,可以直接指定列名。
文档:https://doris.apache.org/zh-CN/docs/dev/data-operate/update-delete/sequence-column-manual
show backends和show tablets返回结果中,增加远端存储的空间使用情况 (#11450)- 移除了 Num-Based Compaction 相关代码(#13409)
- 重构了BE的错误码机制,部分返回的错误信息会发生变化(#8855)
其他
- 支持Docker 官方镜像。
- 支持在 MacOS(x86/M1) 和 ubuntu-22.04 上编译 Doris
- 支持进行image 文件的校验。
文档搜索“--image”:https://doris.apache.org/zh-CN/docs/dev/admin-manual/maint-monitor/metadata-operation
- 脚本相关
- FE、BE 的 stop 脚本支持通过
--grace参数退出FE、BE(使用 kill -15 信号代替 kill -9) - FE start 脚本支持通过 --version 查看当前FE 版本(#11563)
- FE、BE 的 stop 脚本支持通过
- 支持通过
ADMIN COPY TABLET命令获取某个 tablet 的数据和相关建表语句,用于本地问题调试
- 支持通过 http api,获取一个SQL语句相关的 建表语句,用于本地问题复现
文档:https://doris.apache.org/zh-CN/docs/dev/admin-manual/http-actions/fe/query-schema-action
- 支持建表时关闭这个表的 compaction 功能,用于测试
文档中搜索 "disble_auto_compaction":https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Definition-Statements/Create/CREATE-TABLE
致谢
Apache Doris 1.2.0 版本的发布离不开所有社区用户的支持,在此向所有参与版本设计、开发、测试、讨论的社区贡献者们表示感谢,他们分别是(首字母排序):
@924060929
@a19920714liou
@adonis0147
@Aiden-Dong
@aiwenmo
@AshinGau
@b19mud
@BePPPower
@BiteTheDDDDt
@bridgeDream
@ByteYue
@caiconghui
@CalvinKirs
@cambyzju
@caoliang-web
@carlvinhust2012
@catpineapple
@ccoffline
@chenlinzhong
@chovy-3012
@coderjiang
@cxzl25
@dataalive
@dataroaring
@dependabot
@dinggege1024
@DongLiang-0
@Doris-Extras
@eldenmoon
@EmmyMiao87
@englefly
@FreeOnePlus
@Gabriel39
@gaodayue
@geniusjoe
@gj-zhang
@gnehil
@GoGoWen
@HappenLee
@hello-stephen
@Henry2SS
@hf200012
@huyuanfeng2018
@jacktengg
@jackwener
@jeffreys-cat
@Jibing-Li
@JNSimba
@Kikyou1997
@Lchangliang
@LemonLiTree
@lexoning
@liaoxin01
@lide-reed
@link3280
@liutang123
@liuyaolin
@LOVEGISER
@lsy3993
@luozenglin
@luzhijing
@madongz
@morningman
@morningman-cmy
@morrySnow
@mrhhsg
@Myasuka
@myfjdthink
@nextdreamblue
@pan3793
@pangzhili
@pengxiangyu
@platoneko
@qidaye
@qzsee
@SaintBacchus
@SeekingYang
@smallhibiscus
@sohardforaname
@song7788q
@spaces-X
@ssusieee
@stalary
@starocean999
@SWJTU-ZhangLei
@TaoZex
@timelxy
@Wahno
@wangbo
@wangshuo128
@wangyf0555
@weizhengte
@weizuo93
@wsjz
@wunan1210
@xhmz
@xiaokang
@xiaokangguo
@xinyiZzz
@xy720
@yangzhg
@Yankee24
@yeyudefeng
@yiguolei
@yinzhijian
@yixiutt
@yuanyuan8983
@zbtzbtzbt
@zenoyang
@zhangboya1
@zhangstar333
@zhannngchen
@ZHbamboo
@zhengshiJ
@zhenhb
@zhqu1148980644
@zuochunwei
@zy-kkk
