跨集群数据同步
概览
CCR 是什么
CCR(Cross Cluster Replication) 是跨集群数据同步,能够在库/表级别将源集群的数据变更同步到目标集群,可用于在线服务的数据可用性、隔离在离线负载、建设两地三中心。
适用场景
CCR 通常被用于容灾备份、读写分离、集团与公司间数据传输和隔离升级等场景。
容灾备份:通常是将企业的数据备份到另一个集群与机房中,当突发事件导致业务中断或丢失时,可以从备份中恢复数据或快速进行主备切换。一般在对 SLA 要求比较高的场景中,都需要进行容灾备份,比如在金融、医疗、电子商务等领域中比较常见。
读写分离:读写分离是将数据的查询操作和写入操作进行分离,目的是降低读写操作的相互影响并提升资源的利用率。比如在数据库写入压力过大或在高并发场景中,采用读写分离可以将读/写操作分散到多个地域的只读/只写的数据库案例上,减少读写间的互相影响,有效保证数据库的性能及稳定性。
集团与分公司间数据传输:集团总部为了对集团内数据进行统一管控和分析,通常需要分布在各地域的分公司及时将数据传输同步到集团总部,避免因为数据不一致而引起的管理混乱和决策错误,有利于提高集团的管理效率和决策质量。
隔离升级:当在对系统集群升级时,有可能因为某些原因需要进行版本回滚,传统的升级模式往往会因为元数据不兼容的原因无法回滚。而使用 CCR 可以解决该问题,先构建一个备用的集群进行升级并双跑验证,用户可以依次升级各个集群,同时 CCR 也不依赖特定版本,使版本的回滚变得可行。
任务类别
CCR 支持两个类别的任务,分别是库级别和表级别,库级别的任务同步一个库的数据,表级别的任务只同步一个表的数据。
原理与架构
名词解释
源集群:源头集群,业务数据写入的集群,需要 2.0 版本
目标集群:跨集群同步的目标集群,需要 2.0 版本
binlog:源集群的变更日志,包括 schema 和数据变更
syncer:一个轻量级的进程
上游:库级别任务时指上游库,表级别任务时指上游表。
下游:库级别任务时指下游库,表级别人物时指下游表。
架构说明
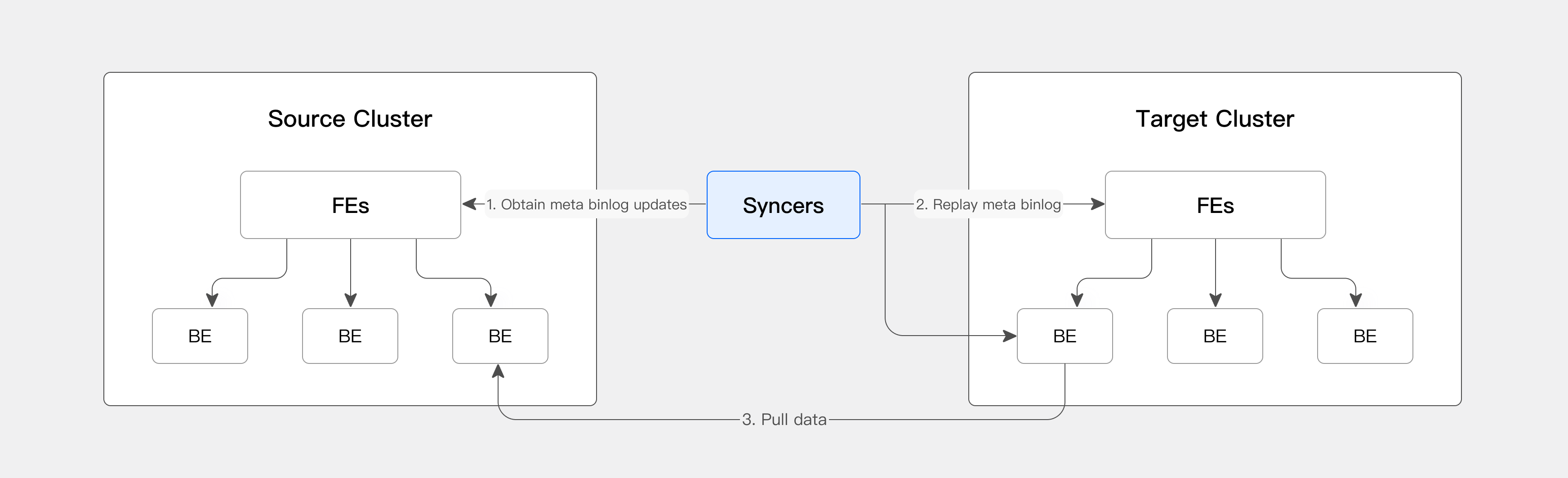
CCR 工具主要依赖一个轻量级进程:Syncers。Syncers 会从源集群获取 binlog,直接将元数据应用于目标集群,通知目标集群从源集群拉取数据。从而实现全量和增量迁移。
同步方式
CCR 支持四种同步方式:
| 同步方式 | 原理 | 触发时机 |
|---|---|---|
| Full Sync | 上游全量backup,下游restore。 | 首次同步或者操作触发,操作见功能列表。 |
| Partial Sync | 上游表或者分区级别 Backup,下游表或者分区级别restore。 | 操作触发,操作见功能列表。 |
| TXN | 增量数据同步,上游提交之后,下游开始同步。 | 操作触发,操作见功能列表。 |
| SQL | 在下游回放上游操作的 SQL。 | 操作触发,操作见功能列表。 |
使用
使用非常简单,只需把 Syncers 服务启动,给他发一个命令,剩下的交给 Syncers 完成就行。
1. 部署源 Doris 集群
2. 部署目标 Doris 集群
3. 首先源集群和目标集群都需要打开 binlog,在源集群和目标集群的 fe.conf 和 be.conf 中配置如下信息:
enable_feature_binlog=true
4. 部署 syncers
构建 CCR syncer
git clone https://github.com/selectdb/ccr-syncer
cd ccr-syncer
bash build.sh <-j NUM_OF_THREAD> <--output SYNCER_OUTPUT_DIR>
cd SYNCER_OUTPUT_DIR# 联系相关同学免费获取 ccr 二进制包启动和停止 syncer
# 启动
cd bin && sh start_syncer.sh --daemon
# 停止
sh stop_syncer.sh
5. 打开源集群中同步库/表的 Binlog
-- 如果是整库同步,可以执行如下脚本,使得该库下面所有的表都要打开 binlog.enable
vim shell/enable_db_binlog.sh
修改源集群的 host、port、user、password、db
或者 ./enable_db_binlog.sh --host $host --port $port --user $user --password $password --db $db
-- 如果是单表同步,则只需要打开 table 的 binlog.enable,在源集群上执行:
ALTER TABLE enable_binlog SET ("binlog.enable" = "true");
6. 向 syncer 发起同步任务
curl -X POST -H "Content-Type: application/json" -d '{
"name": "ccr_test",
"src": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "your_db_name",
"table": "your_table_name"
},
"dest": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "your_db_name",
"table": "your_table_name"
}
}' http://127.0.0.1:9190/create_ccr
同步任务的参数说明:
name: CCR同步任务的名称,唯一即可
host、port:对应集群 Master FE的host和mysql(jdbc) 的端口
user、password:syncer以何种身份去开启事务、拉取数据等
database、table:
如果是库级别的同步,则填入your_db_name,your_table_name为空
如果是表级别同步,则需要填入your_db_name,your_table_name
向syncer发起同步任务中的name只能使用一次
Syncer 详细操作手册
启动 Syncer 说明
根据配置选项启动 Syncer,并且在默认或指定路径下保存一个 pid 文件,pid 文件的命名方式为host_port.pid。
输出路径下的文件结构
在编译完成后的输出路径下,文件结构大致如下所示:
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # 默认配置下运行后生成
log
[ccr_syncer.log] # 默认配置下运行后生成
后文中的 start_syncer.sh 指的是该路径下的 start_syncer.sh!!!
启动选项
- --daemon
后台运行 Syncer,默认为 false
bash bin/start_syncer.sh --daemon
- --db_type
Syncer 目前能够使用两种数据库来保存自身的元数据,分别为sqlite3(对应本地存储)和mysql(本地或远端存储)
bash bin/start_syncer.sh --db_type mysql
默认值为 sqlite3
在使用 mysql 存储元数据时,Syncer 会使用CREATE IF NOT EXISTS来创建一个名为ccr的库,ccr 相关的元数据表都会保存在其中
- --db_dir
这个选项仅在 db 使用 sqlite3 时生效
可以通过此选项来指定 sqlite3 生成的 db 文件名及路径。
bash bin/start_syncer.sh --db_dir /path/to/ccr.db
默认路径为SYNCER_OUTPUT_DIR/db,文件名为ccr.db
- --db_host & db_port & db_user & db_password
这个选项仅在 db 使用 mysql 时生效
bash bin/start_syncer.sh --db_host 127.0.0.1 --db_port 3306 --db_user root --db_password "qwe123456"
db_host、db_port 的默认值如例子中所示,db_user、db_password 默认值为空
- --log_dir
日志的输出路径
bash bin/start_syncer.sh --log_dir /path/to/ccr_syncer.log
默认路径为SYNCER_OUTPUT_DIR/log,文件名为ccr_syncer.log
- --log_level
用于指定 Syncer 日志的输出等级。
bash bin/start_syncer.sh --log_level info
日志的格式如下,其中 hook 只会在log_level > info的时候打印:
# time level msg hooks
[2023-07-18 16:30:18] TRACE This is trace type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] DEBUG This is debug type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] INFO This is info type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] WARN This is warn type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] ERROR This is error type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] FATAL This is fatal type. ccrName=xxx line=xxx
在--daemon 下,log_level 默认值为info
在前台运行时,log_level 默认值为trace,同时日志会通过 tee 来保存到 log_dir
- --host && --port
用于指定 Syncer 的 host 和 port,其中 host 只起到在集群中的区分自身的作用,可以理解为 Syncer 的 name,集群中 Syncer 的名称为host:port
bash bin/start_syncer.sh --host 127.0.0.1 --port 9190
host 默认值为 127.0.0.1,port 的默认值为 9190
- --pid_dir
用于指定 pid 文件的保存路径
pid 文件是 stop_syncer.sh 脚本用于关闭 Syncer 的凭据,里面保存了对应 Syncer 的进程号,为了方便 Syncer 的集群化管理,可以指定 pid 文件的保存路径
bash bin/start_syncer.sh --pid_dir /path/to/pids
默认值为SYNCER_OUTPUT_DIR/bin
Syncer 停止说明
根据默认或指定路径下 pid 文件中的进程号关闭对应 Syncer,pid 文件的命名方式为host_port.pid。
输出路径下的文件结构
在编译完成后的输出路径下,文件结构大致如下所示:
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # 默认配置下运行后生成
log
[ccr_syncer.log] # 默认配置下运行后生成
后文中的 stop_syncer.sh 指的是该路径下的 stop_syncer.sh!!!
停止选项
有三种关闭方法:
- 关闭目录下单个 Syncer
指定要关闭 Syncer 的 host && port,注意要与 start_syncer 时指定的 host 一致
- 批量关闭目录下指定 Syncer
指定要关闭的 pid 文件名,以空格分隔,用" "包裹
- 关闭目录下所有 Syncer
默认即可
- --pid_dir
指定 pid 文件所在目录,上述三种关闭方法都依赖于 pid 文件的所在目录执行
bash bin/stop_syncer.sh --pid_dir /path/to/pids
例子中的执行效果就是关闭/path/to/pids下所有 pid 文件对应的 Syncers(方法 3),--pid_dir可与上面三种关闭方法组合使用。
默认值为SYNCER_OUTPUT_DIR/bin
- --host && --port
关闭 pid_dir 路径下 host:port 对应的 Syncer
bash bin/stop_syncer.sh --host 127.0.0.1 --port 9190
host 的默认值为 127.0.0.1,port 默认值为空
即,单独指定 host 时方法 1不生效,会退化为方法 3。
host 与 port 都不为空时方法 1才能生效
- --files
关闭 pid_dir 路径下指定 pid 文件名对应的 Syncer
bash bin/stop_syncer.sh --files "127.0.0.1_9190.pid 127.0.0.1_9191.pid"
文件之间用空格分隔,整体需要用" "包裹住
Syncer 操作列表
请求的通用模板
curl -X POST -H "Content-Type: application/json" -d {json_body} http://ccr_syncer_host:ccr_syncer_port/operator
json_body: 以 json 的格式发送操作所需信息
operator:对应 Syncer 的不同操作
所以接口返回都是 json, 如果成功则是其中 success 字段为 true, 类似,错误的时候,是 false,然后存在ErrMsgs字段
{"success":true}
or
{"success":false,"error_msg":"job ccr_test not exist"}
创建任务
curl -X POST -H "Content-Type: application/json" -d '{
"name": "ccr_test",
"src": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "demo",
"table": "example_tbl"
},
"dest": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "ccrt",
"table": "copy"
}
}' http://127.0.0.1:9190/create_ccr
name: CCR 同步任务的名称,唯一即可
host、port:对应集群 master 的 host 和 mysql(jdbc) 的端口
thrift_port:对应 FE 的 rpc_port
user、password:syncer 以何种身份去开启事务、拉取数据等
database、table:
如果是 库级别的同步,则填入 dbName,tableName 为空
如果是表级别同步,则需要填入 dbName、tableName
查看同步进度
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/get_lag
job_name 是 create_ccr 时创建的 name。
暂停任务
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/pause
恢复任务
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/resume
删除任务
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/delete
获取版本
curl http://ccr_syncer_host:ccr_syncer_port/version
# > return
{"version": "2.0.1"}
查看任务状态
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/job_status
{
"success": true,
"status": {
"name": "ccr_db_table_alias",
"state": "running",
"progress_state": "TableIncrementalSync"
}
}
结束同步
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/desync
获取任务列表
curl http://ccr_syncer_host:ccr_syncer_port/list_jobs
{"success":true,"jobs":["ccr_db_table_alias"]}
开启库中所有表的 binlog
输出路径下的文件结构
在编译完成后的输出路径下,文件结构大致如下所示:
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # 默认配置下运行后生成
log
[ccr_syncer.log] # 默认配置下运行后生成
后文中的 enable_db_binlog.sh 指的是该路径下的 enable_db_binlog.sh!!!
使用说明
bash bin/enable_db_binlog.sh -h host -p port -u user -P password -d db
Syncer 高可用
Syncer 高可用依赖 mysql,如果使用 mysql 作为后端存储,Syncer 可以发现其它 syncer,如果一个 crash 了,其他会分担他的任务
权限要求
Select_priv 对数据库、表的只读权限。
Load_priv 对数据库、表的写权限。包括 Load、Insert、Delete 等。
Alter_priv 对数据库、表的更改权限。包括重命名 库/表、添加/删除/变更 列、添加/删除 分区等操作。
Create_priv 创建数据库、表、视图的权限。
drop_priv 删除数据库、表、视图的权限。
加上 Admin 权限 (之后考虑彻底移除), 这个是用来检测 enable binlog config 的,现在需要 admin
使用限制
网络约束
需要 Syncer 与上下游的 FE 和 BE 都是通的
下游 BE 与上游 BE 是通的
对外 IP 和 Doris 内部 IP 是一样的,也就是说
show frontends/backends看到的,和能直接连的 IP 是一致的,要是直连,不能是 IP 转发或者 nat
ThriftPool 限制
开大 thrift thread pool 大小,最好是超过一次 commit 的 bucket 数目大小
版本要求
版本最低要求:v2.0.3
不支持的操作
rename table 支持有点问题
不支持一些 trash 的操作,比如 table 的 drop-recovery 操作
和 rename table 有关的,replace partition 与
不能发生在同一个 db 上同时 backup/restore
Feature
限速
BE 端配置参数:
download_binlog_rate_limit_kbs=1024 # 限制单个 BE 节点从源集群拉取 Binlog(包括 Local Snapshot)的速度为 1 MB/s
详细参数加说明:
download_binlog_rate_limit_kbs参数在源集群 BE 节点配置,通过设置该参数能够有效限制数据拉取速度。download_binlog_rate_limit_kbs参数主要用于设置单个 BE 节点的速度,若计算集群整体速率一般需要参数值乘以集群个数。
IS_BEING_SYNCED 属性
从 Doris v2.0 "is_being_synced" = "true"
CCR 功能在建立同步时,会在目标集群中创建源集群同步范围中表(后称源表,位于源集群)的副本表(后称目标表,位于目标集群),但是在创建副本表时需要失效或者擦除一些功能和属性以保证同步过程中的正确性。
如:
源表中包含了可能没有被同步到目标集群的信息,如
storage_policy等,可能会导致目标表创建失败或者行为异常。源表中可能包含一些动态功能,如动态分区等,可能导致目标表的行为不受 syncer 控制导致 partition 不一致。
在被复制时因失效而需要擦除的属性有:
storage_policycolocate_with
在被同步时需要失效的功能有:
自动分桶
动态分区
实现
在创建目标表时,这条属性将会由 syncer 控制添加或者删除,在 CCR 功能中,创建一个目标表有两个途径:
在表同步时,syncer 通过 backup/restore 的方式对源表进行全量复制来得到目标表。
在库同步时,对于存量表而言,syncer 同样通过 backup/restore 的方式来得到目标表,对于增量表而言,syncer 会通过携带有 CreateTableRecord 的 binlog 来创建目标表。
综上,对于插入is_being_synced属性有两个切入点:全量同步中的 restore 过程和增量同步时的 getDdlStmt。
在全量同步的 restore 过程中,syncer 会通过 rpc 发起对原集群中 snapshot 的 restore,在这个过程中为会为 RestoreStmt 添加is_being_synced属性,并在最终的 restoreJob 中生效,执行isBeingSynced的相关逻辑。在增量同步时的 getDdlStmt 中,为 getDdlStmt 方法添加参数boolean getDdlForSync,以区分是否为受控转化为目标表 ddl 的操作,并在创建目标表时执行isBeingSynced的相关逻辑。
对于失效属性的擦除无需多言,对于上述功能的失效需要进行说明:
自动分桶 自动分桶会在创建表时生效,计算当前合适的 bucket 数量,这就可能导致源表和目的表的 bucket 数目不一致。因此在同步时需要获得源表的 bucket 数目,并且也要获得源表是否为自动分桶表的信息以便结束同步后恢复功能。当前的做法是在获取 distribution 信息时默认 autobucket 为 false,在恢复表时通过检查
_auto_bucket属性来判断源表是否为自动分桶表,如是则将目标表的 autobucket 字段设置为 true,以此来达到跳过计算 bucket 数量,直接应用源表 bucket 数量的目的。动态分区 动态分区则是通过将
olapTable.isBeingSynced()添加到是否执行 add/drop partition 的判断中来实现的,这样目标表在被同步的过程中就不会周期性的执行 add/drop partition 操作。
注意
在未出现异常时,is_being_synced属性应该完全由 syncer 控制开启或关闭,用户不要自行修改该属性。
