Lakehouse Overview
Before the integration of data lake and data warehouse, the history of data analysis went through three eras: database, data warehouse, and data lake analytics.
- Database, the fundamental concept, was primarily responsible for online transaction processing and providing basic data analysis capabilities.
- As data volumes grew, data warehouses emerged. They store valuable data that has been cleansed, processed, and modeled, providing analytics capabilities for business.
- The advent of data lakes was to serve the needs of enterprises for storing, managing, and reprocessing raw data. They required low-cost storage for structured, semi-structured, and even unstructured data, and they also needed an integrated solution encompassing data processing, data management, and data governance.
Data warehouses addresses the need for fast data analysis, while data lakes are good at data storage and management. The integration of them, known as "lakehouse", is to facilitate the seamless integration and free flow of data between the data lake and data warehouse. It enables users to leverage the analytic capabilities of the data warehouse while harnessing the data management power of the data lake.
Applicable scenarios
We design the Doris lakehouse solution for the following four applicable scenarios:
- Lakehouse query acceleration: As a highly efficient OLAP query engine, Doris has excellent MPP-based vectorized distributed query capabilities. Data lake analysis with Doris will benefit from the efficient query engine.
- Unified data analysis gateway: Doris provides data query and writing capabilities for various and heterogeneous data sources. Users can unify these external data sources onto Doris' data mapping structure, allowing for a consistent query experience when accessing external data sources through Doris.
- Unified data integration: Doris, through its data lake integration capabilities, enables incremental or full data synchronization from multiple data sources to Doris. Doris processes the synchronized data and makes it available for querying. The processed data can also be exported to downstream systems as full or incremental data services. Using Doris, you can have less reliance on external tools and enable end-to-end connectivity from ata synchronization to data processing.
- More open data platform: Many data warehouses have their own storage formats. They require external data to be imported into themselve before the data queryable. This creates a closed ecosystem where data in the data warehouse can only be accessed by the data warehouse itself. In this case, users might concern if data will be locked into a specific data warehouse or wonder if there are any other easy way for data export. The Doris lakehouse solution provides open data formats, such as Parquet/ORC, to allow data access by various external systems. Additionally, just like Iceberg and Hudi providing open metadata management capabilities, metadata, whether stored in Doris, Hive Metastore, or other unified metadata centers, can be accessed through publicly available APIs. An open data ecosystem makes it easy for enterprises to migrate to new data management systems and reduces the costs and risks in this process.
Doris-based data lakehouse architecture
Apache Doris can work as a data lakehouse with its Multi Catalog feature. It can access databases and data lakes including Apache Hive, Apache Iceberg, Apache Hudi, Apache Paimon (incubating), Elasticsearch, MySQL, Oracle, and SQLServer. It also supports Apache Ranger for privilege management.
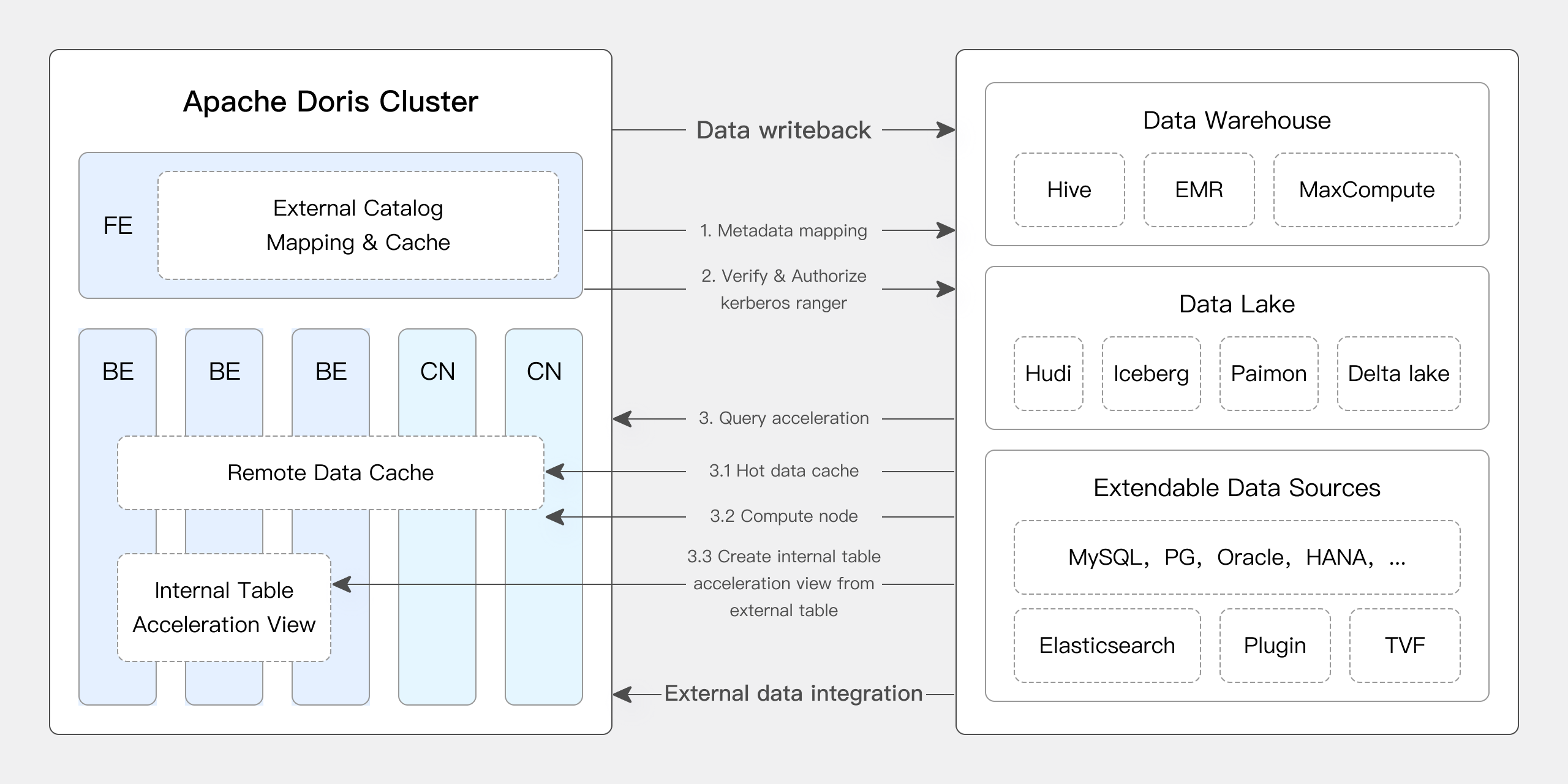
Data access steps:
- Create metadata mapping: Apache Doris fetches metadata via Catalog and caches it for metadata management. For metadata mapping, it supports JDBC username-password authentication, Kerberos/Ranger-based authentication, and KMS-based data encryption.
- Launch query request: When the user launches a query request from the Doris frontend (FE), Doris generates a query plan based on its cached metadata. Then, it utilizes the Native Reader to fetch data from external storage (HDFS, S3) for data computation and analysis. During query execution, it caches the hot data to prepare for similar queries in the future.
- Return result: When a query is finished, it returns the query result on the frontend.
- Write result to data lake: For users who need to write the result back to the data lake instead of returning it on the frontend, Doris supports result writeback in CSV, Parquet, and ORC formats via the export method to the data lake.
Core technologies
Apache Doris empowers data lake analytics with its extensible connection framework, metadata caching, data caching, NativeReader, I/O optimization, and statistics collection capabilities.
Extensible connection framework
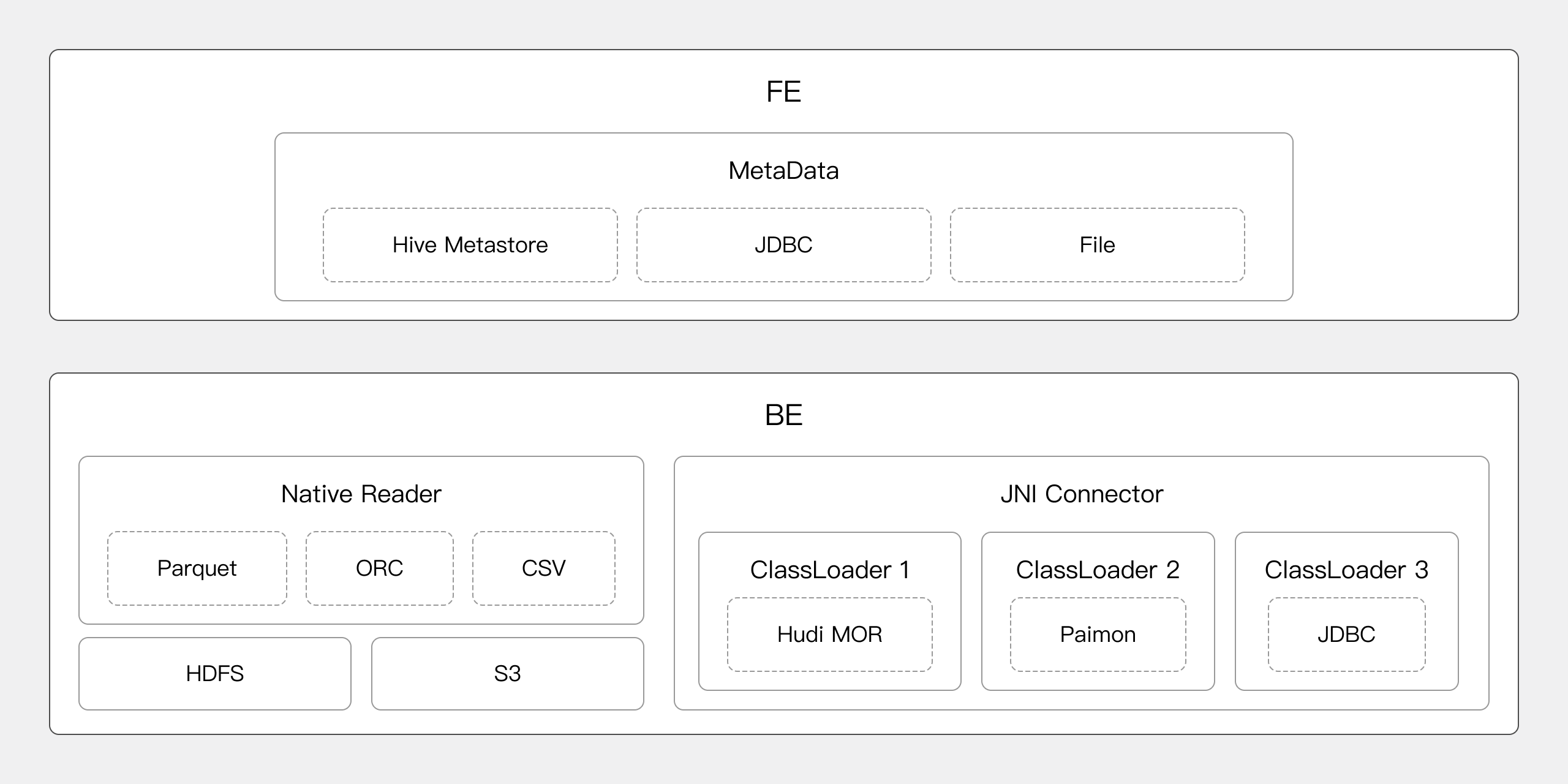
The data connection framework in Apache Doris includes metadata connection and data reading.
- Metadata connection: Metadata connection is conducted in the frontend of Doris. The MetaData Manager in the frontend can access and manage metadata from Hive Metastore, JDBC, and data files.
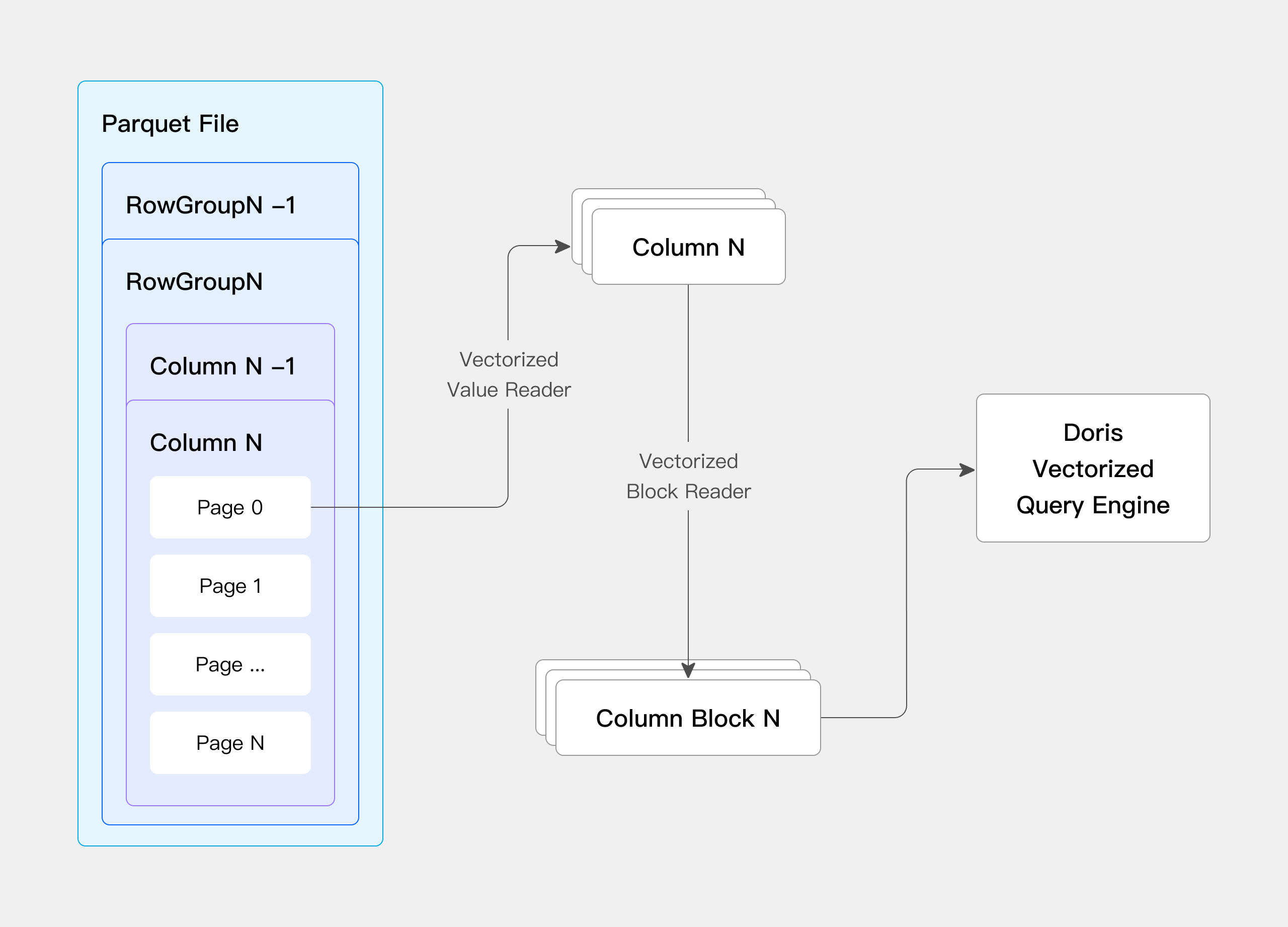
- Data reading: Apache Doris has a NativeReader for efficient data reading from HDFS and object storage. It supports Parquet, ORC, and text data. You can also connect Apache Doris to the Java big data ecosystem via its JNI Connector.
Efficient caching strategy
Apache Doris caches metadata, data, and query results to improve query performance.
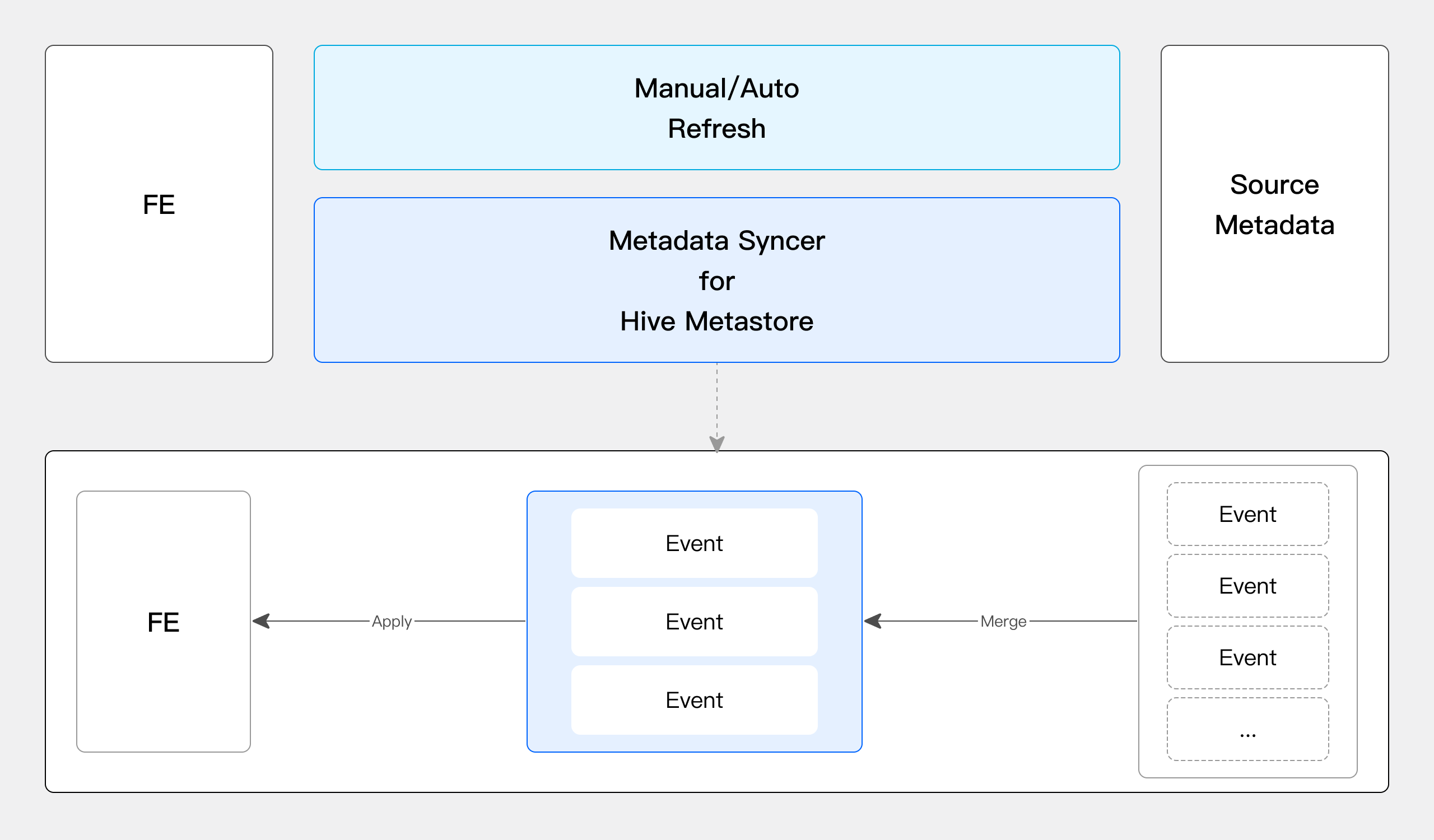
Metadata caching
Apache Doris supports metadata synchronization by three methods: auto synchronization, periodic synchronization, and metadata subscription (for Hive Metastore only). It accesses metadata from the data lake and stores it in the memory of its frontend. When a user issues a query request, Doris can quickly fetch metadata from its own memory and generate a query plan accordingly. Apache Doris improves synchronization efficiency by merging the concurrent metadata events. It can process over 100 metadata events per second.
Data caching
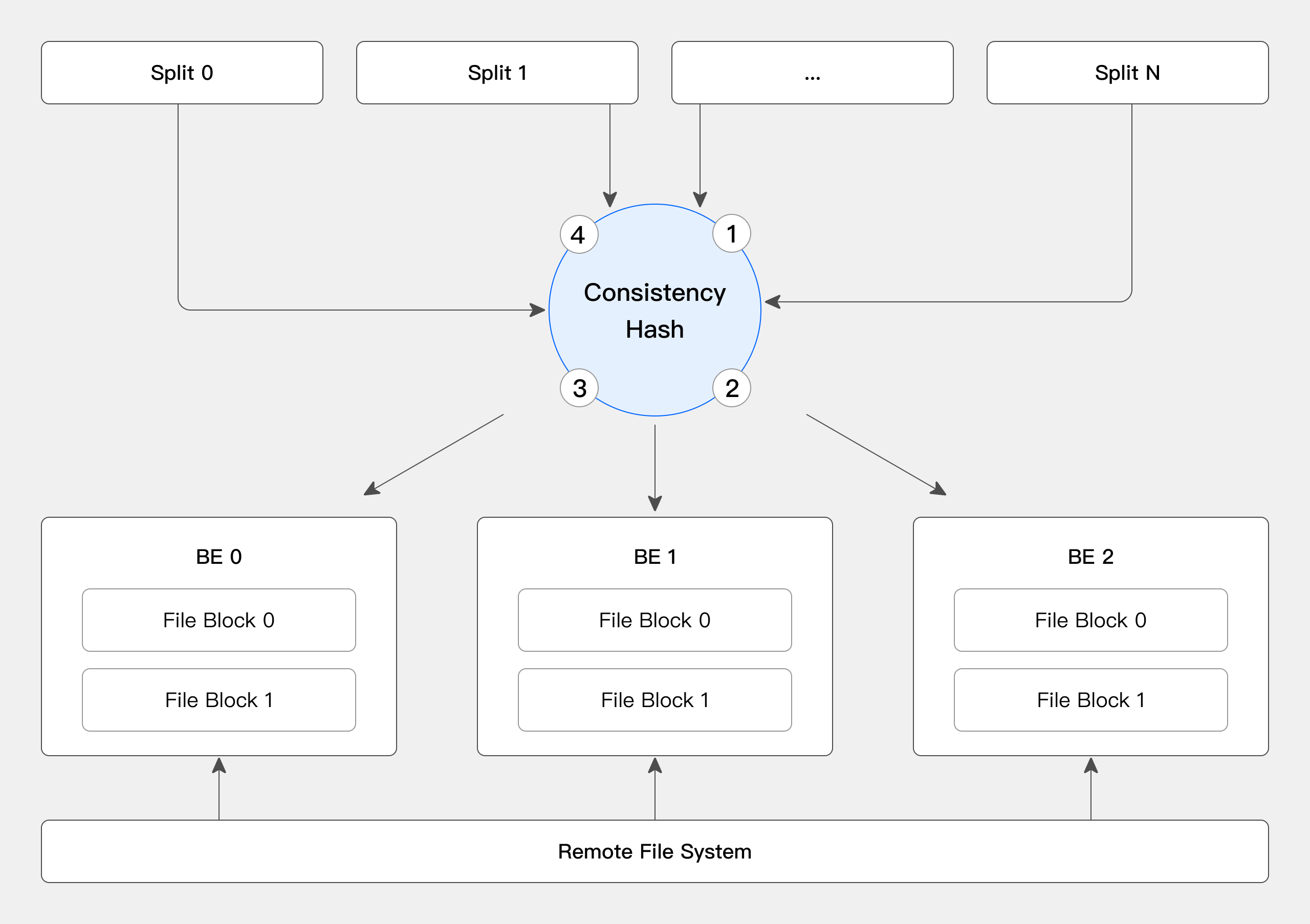
- File caching: Apache Doris caches hot data from the data lake onto its local disks to reduce data transfer via the network and increase data access efficiency.
- Cache distribution: Apache Doris distributes the cached data across all backend nodes via consistent hashing to avoid cache expiration caused by cluster scaling.
- Cache eviction(update): When Apache Doris detects changes in the metadata of a data file, it promptly updates its cached data to ensure data consistency.
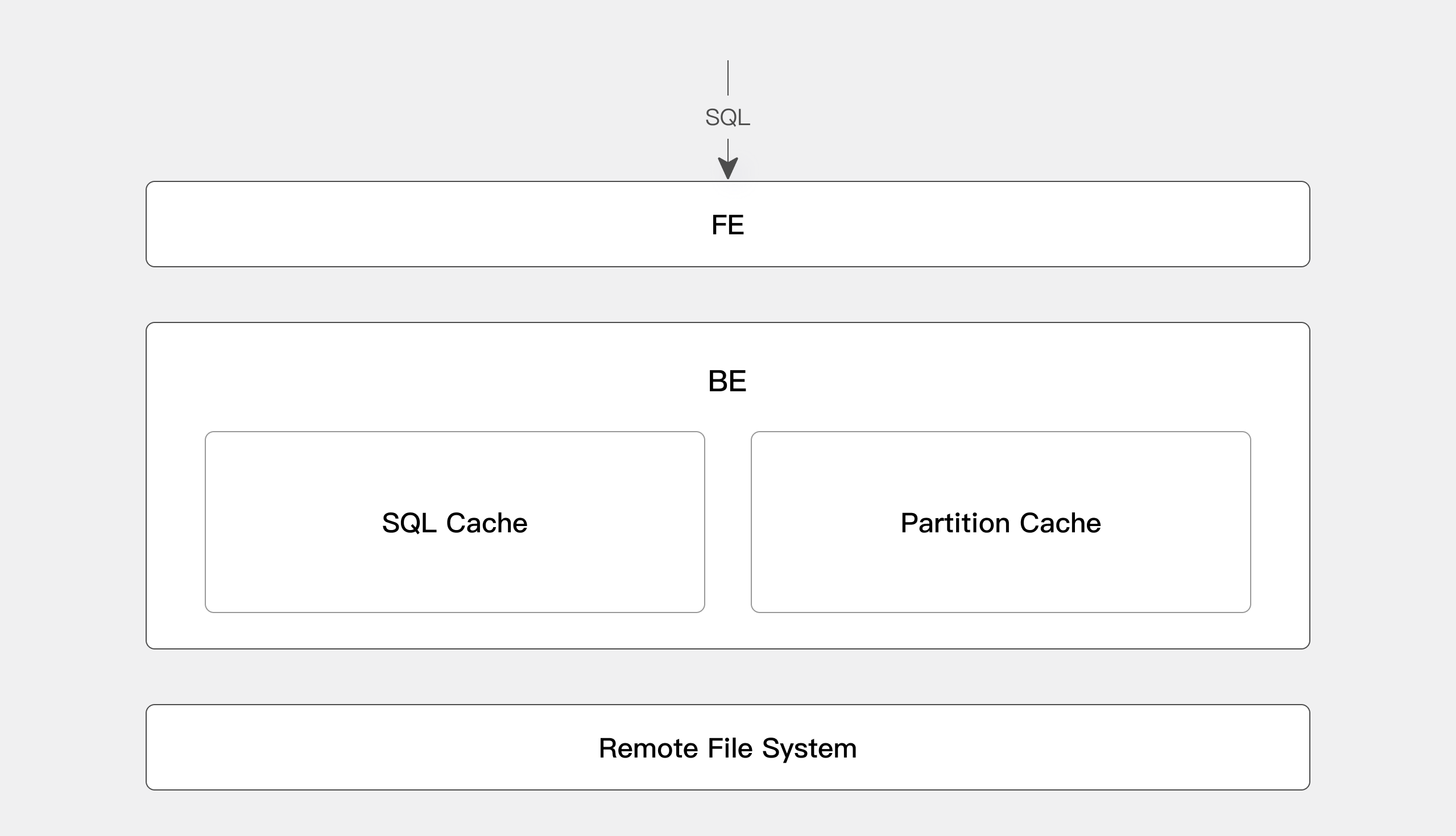
Query result caching & partition caching
- Query result caching: Apache Doris caches the results of previous SQL queries, so it can reuse them when similar queries are launched. It will read the corresponding result from the cache directly and return it to the client. This increases query efficiency and concurrency.
- Partition caching: Apache Doris allows you to cache part of your data partitions in the backend to increase query efficiency. For example, if you need the data from the past 7 days (counting today), you can cache the data from the previous 6 days and merge it with today's data. This can largely reduce real-time computation burden and increase speed.
Native Reader
- Self-developed Native Reader to avoid data conversion: Apache Doris has its own columnar storage format, which is different from Parquet and ORC. To avoid overheads caused by data format conversion, we have built our own Native Reader for Parquet and ORC files.
- Lazy materialization: The Native Reader can utilize indexes and filters to improve data reading. For example, when the user needs to do filtering based on the ID column, what the Native Reader does is to read and filter the ID column, take note of the relevant row numbers, and then read the corresponding rows of the other columns based on the row numbers recorded. This reduces data scanning and speeds up data reading.
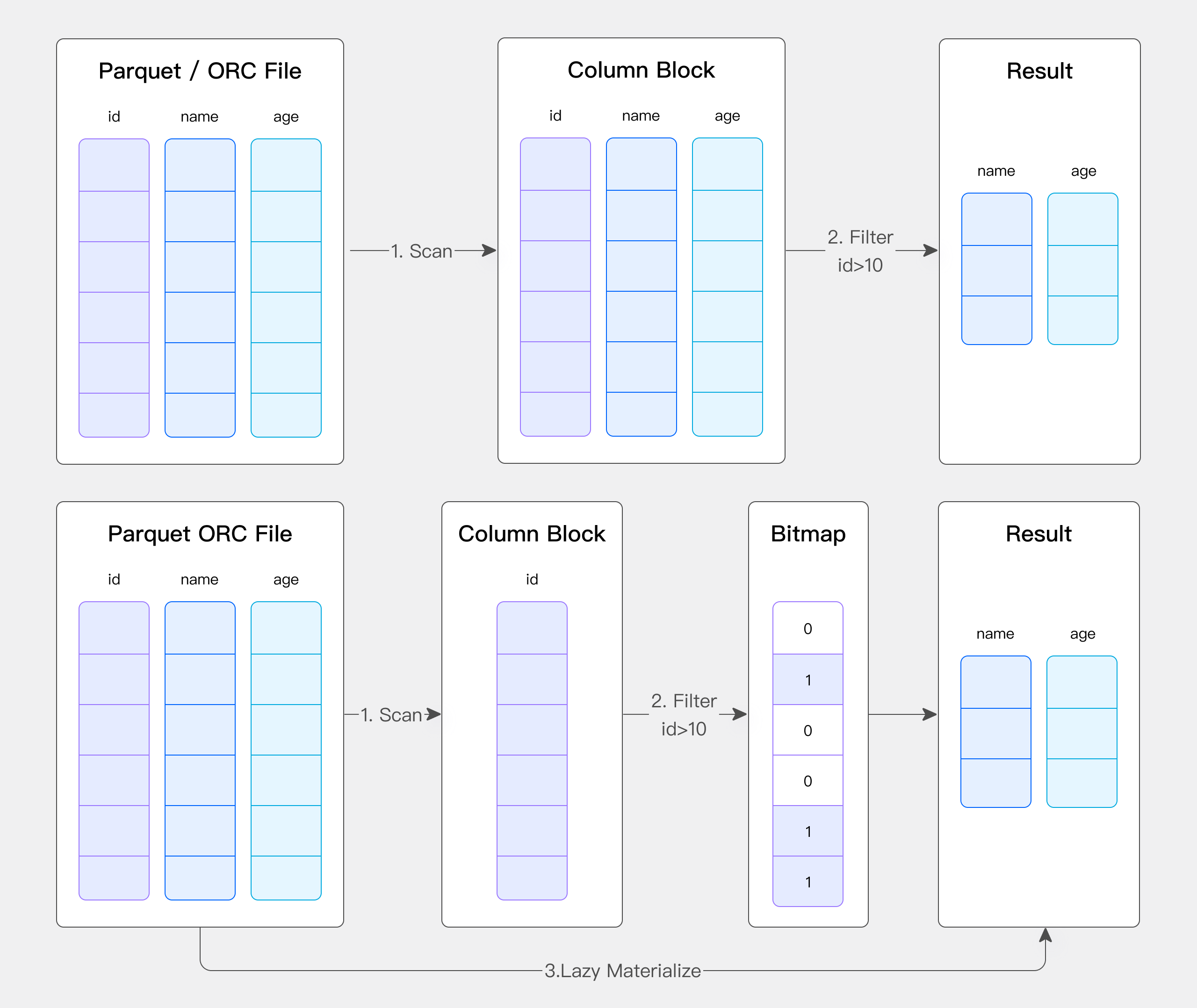
- Vectorized data reading: We have vectorized data file reading in Apache Doris to increase reading speed.
Merge I/O
A large number of small file network I/O requests can reduce I/O performance. To solve that, we introduce an I/O merging mechanism.
For example, if you decide to merge any I/O requests smaller than 3MB, then instead of dealing with all 8 small I/O requests separately, the system only needs to read 5 timess. That's how it improves data access efficiency.
The downside of I/O merging is that it might read some irrelevant data, because it merges and reads together some intermediate data that might not be needed. Despite that, I/O merging can still bring a significant increase in overall throughput, especially for use cases with a large number of small files (1KB~1MB). Besides, users can mitigate the downside by adjusting the size of I/O merging.

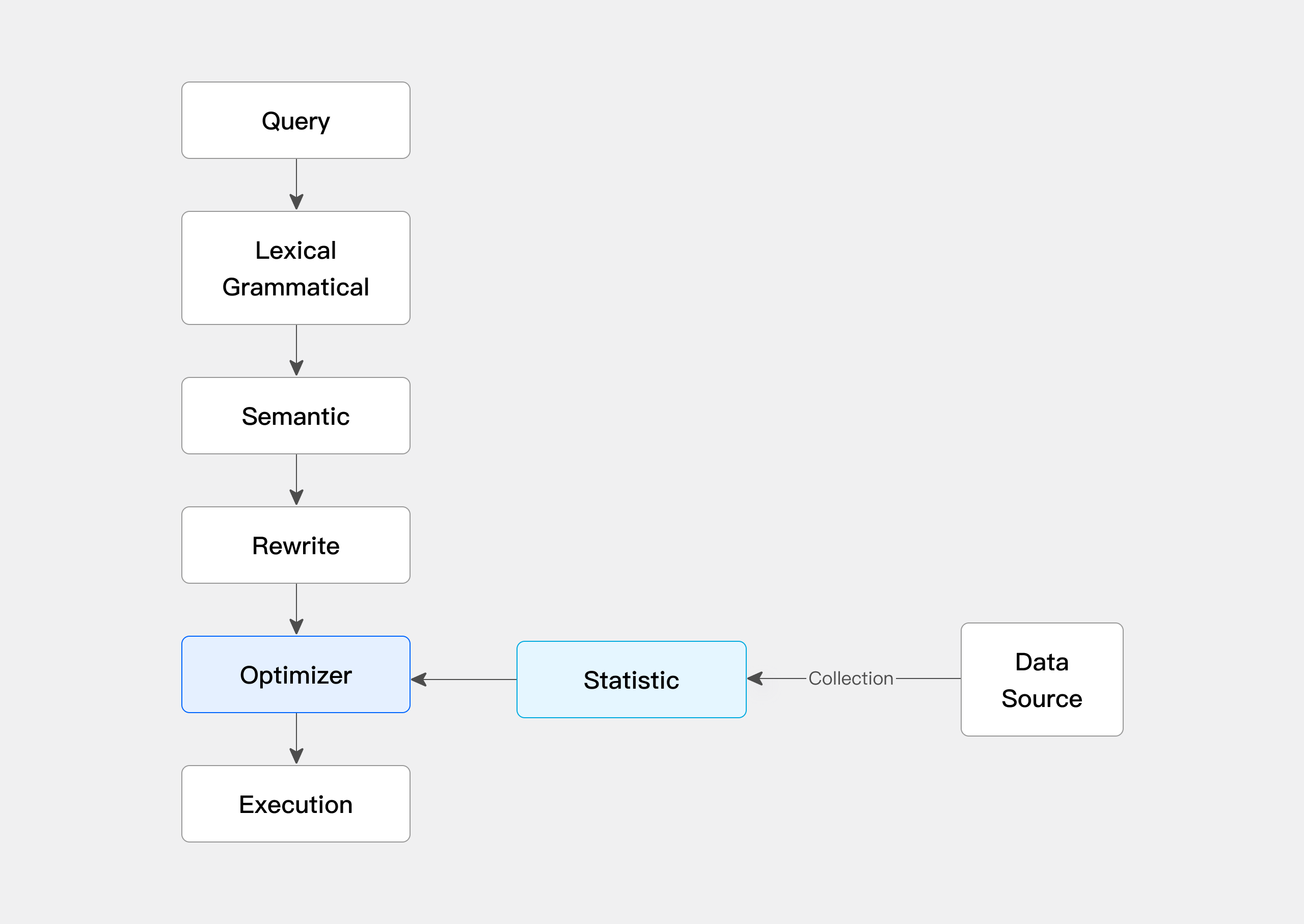
Statistics collection
Apache Doris collects statistical information to help the CBO understand data distribution, so that the CBO can evaluate the feasibility of each predicate and the cost of each execution plan. This helps the CBO figure out the most efficient query plan. It is also applicable in data lake analytics scenarios.
Methods of statistics collection include manual collection and auto collection.
Meanwhile, to avoid pressure on the Doris backend, we have enabled sampling collection of statistics.
In some cases, some data is frequently accessed while others are not, so Apache Doris allows partition-based statistics collection, so it can ensure high efficiency in hot data queries while mitigating the impact of statistics collection on the backend.
Multi-Catalog
Multi-Catalog is designed to facilitate connection to external data catalogs and enhance the data lake analysis and federated data query capabilities of Doris.
In older versions of Doris, user data is in a two-tiered structure: database and table. Thus, connections to external catalogs could only be done at the database or table level. For example, users could create a mapping to a table in an external catalog via create external table, or to a database via create external database. If there are large amounts of databases or tables in the external catalog, users will need to create mappings to them one by one, which could be tedious.
With Multi-Catalog, Doris now has a new three-tiered metadata hierarchy (catalog -> database -> table), which means users can connect to external data at the catalog level directly.
Multi-Catalog works as an additional and enhanced external table connection method. It helps users conduct multi-catalog federated queries quickly.
Basic concepts
- Internal Catalog
Existing databases and tables in Doris are all under the Internal Catalog, which is the default catalog in Doris and cannot be modified or deleted.
- External Catalog
Users can create an External Catalog using the CREATE CATALOG command, and view the existing Catalogs via the SHOW CATALOGS command.
- Switch Catalog
After logging in to Doris, you will enter the Internal Catalog by default. Then, you can view or switch to your target database via SHOW DATABASES and USE DB .
Example:
SWITCH internal;
SWITCH hive_catalog;
After switching catalog, you can view or switch to your target database in that catalog via SHOW DATABASES and USE DB. You can view and access data in External Catalogs the same way as doing that in the Internal Catalog.
- Delete Catalog
You cand delete an External Catalog via the DROP CATALOG command. (The Internal Catalog cannot be deleted.) The deletion only removes the mapping in Doris to the corresponding catalog. It doesn't change the external catalog in external data sources by all means.
Examples
Connect to Hive
The following is the instruction on how to connect to a Hive catalog using the Catalog feature.
For more information about connecting to Hive, please see Hive Catalog.
- Create Catalog
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.21.0.1:7004'
);
Syntax help: CREATE CATALOG
- View Catalog
- View existing Catalogs via the
SHOW CATALOGScommand:
mysql> SHOW CATALOGS;
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
| CatalogId | CatalogName | Type | IsCurrent | CreateTime | LastUpdateTime | Comment |
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
| 10024 | hive | hms | yes | 2023-12-25 16:11:41.687 | 2023-12-25 20:43:18 | NULL |
| 0 | internal | internal | | UNRECORDED | NULL | Doris internal catalog |
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
- SHOW CATALOGS
- You can view the CREATE CATALOG statement via SHOW CREATE CATALOG.
- You can modify the Catalog PROPERTIES via ALTER CATALOG.
- Switch Catalog
Switch to the Hive Catalog using the SWITCH command, and view the databases in it:
mysql> SWITCH hive;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW DATABASES;
+-----------+
| Database |
+-----------+
| default |
| random |
| ssb100 |
| tpch1 |
| tpch100 |
| tpch1_orc |
+-----------+
Syntax help: SWITCH
- Use the Catalog
After switching to the Hive Catalog, you can use the relevant features.
For example, you can switch to Database tpch100, and view the tables in it:
mysql> USE tpch100;
Database changed
mysql> SHOW TABLES;
+-------------------+
| Tables_in_tpch100 |
+-------------------+
| customer |
| lineitem |
| nation |
| orders |
| part |
| partsupp |
| region |
| supplier |
+-------------------+
You can view the schema of Table lineitem:
mysql> DESC lineitem;
+-----------------+---------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+---------------+------+------+---------+-------+
| l_shipdate | DATE | Yes | true | NULL | |
| l_orderkey | BIGINT | Yes | true | NULL | |
| l_linenumber | INT | Yes | true | NULL | |
| l_partkey | INT | Yes | true | NULL | |
| l_suppkey | INT | Yes | true | NULL | |
| l_quantity | DECIMAL(15,2) | Yes | true | NULL | |
| l_extendedprice | DECIMAL(15,2) | Yes | true | NULL | |
| l_discount | DECIMAL(15,2) | Yes | true | NULL | |
| l_tax | DECIMAL(15,2) | Yes | true | NULL | |
| l_returnflag | TEXT | Yes | true | NULL | |
| l_linestatus | TEXT | Yes | true | NULL | |
| l_commitdate | DATE | Yes | true | NULL | |
| l_receiptdate | DATE | Yes | true | NULL | |
| l_shipinstruct | TEXT | Yes | true | NULL | |
| l_shipmode | TEXT | Yes | true | NULL | |
| l_comment | TEXT | Yes | true | NULL | |
+-----------------+---------------+------+------+---------+-------+
You can perform a query:
mysql> SELECT l_shipdate, l_orderkey, l_partkey FROM lineitem limit 10;
+------------+------------+-----------+
| l_shipdate | l_orderkey | l_partkey |
+------------+------------+-----------+
| 1998-01-21 | 66374304 | 270146 |
| 1997-11-17 | 66374304 | 340557 |
| 1997-06-17 | 66374400 | 6839498 |
| 1997-08-21 | 66374400 | 11436870 |
| 1997-08-07 | 66374400 | 19473325 |
| 1997-06-16 | 66374400 | 8157699 |
| 1998-09-21 | 66374496 | 19892278 |
| 1998-08-07 | 66374496 | 9509408 |
| 1998-10-27 | 66374496 | 4608731 |
| 1998-07-14 | 66374592 | 13555929 |
+------------+------------+-----------+
Or you can conduct a join query:
mysql> SELECT l.l_shipdate FROM hive.tpch100.lineitem l WHERE l.l_partkey IN (SELECT p_partkey FROM internal.db1.part) LIMIT 10;
+------------+
| l_shipdate |
+------------+
| 1993-02-16 |
| 1995-06-26 |
| 1995-08-19 |
| 1992-07-23 |
| 1998-05-23 |
| 1997-07-12 |
| 1994-03-06 |
| 1996-02-07 |
| 1997-06-01 |
| 1996-08-23 |
+------------+
- The table is identified in the format of
catalog.database.table. For example,internal.db1.partin the above snippet. - If the target table is in the current Database of the current Catalog,
cataloganddatabasein the format can be omitted. - You can use the
INSERT INTOcommand to insert table data from the Hive Catalog into a table in the Internal Catalog. This is how you can import data from External Catalogs to the Internal Catalog:
mysql> SWITCH internal;
Query OK, 0 rows affected (0.00 sec)
mysql> USE db1;
Database changed
mysql> INSERT INTO part SELECT * FROM hive.tpch100.part limit 1000;
Query OK, 1000 rows affected (0.28 sec)
{'label':'insert_212f67420c6444d5_9bfc184bf2e7edb8', 'status':'VISIBLE', 'txnId':'4'}
Column type mapping
After you create a Catalog, Doris will automatically synchronize the databases and tables from the corresponding external catalog to it. The following shows how Doris maps different types of catalogs and tables.
As for types that cannot be mapped to a Doris column type, such as UNION and INTERVAL , Doris will map them as the UNSUPPORTED type. Here are examples of queries in a table containing UNSUPPORTED types:
Suppose the table is of the following schema:
k1 INT,
k2 INT,
k3 UNSUPPORTED,
k4 INT
select * from table; // Error: Unsupported type 'UNSUPPORTED_TYPE' in 'k3
select * except(k3) from table; // Query OK.
select k1, k3 from table; // Error: Unsupported type 'UNSUPPORTED_TYPE' in 'k3
select k1, k4 from table; // Query OK.
You can find more details of the mapping of various data sources (Hive, Iceberg, Hudi, Elasticsearch, and JDBC) in the corresponding pages.
Privilege management
When using Doris to access the data in the External Catalog, by default, it relies on Doris's own permission access management function.
Along with the new Multi-Catalog feature, we also added privilege management at the Catalog level (See Privilege Management for details).
Users can also specify a custom authentication class through access_controller.class. For example, if you specify it as
"access_controller.class" = "org.apache.doris.catalog.authorizer.RangerHiveAccessControllerFactory", then you can use Apache Ranger to perform authentication management on Hive Catalog. For more information see: Hive
Database synchronization management
Set include_database_list and exclude_database_list in Catalog properties to specify the databases to synchronize.
include_database_list: only synchronize the specified databases, split with ,. The default setting is to synchronize all databases. The database names are case-sensitive.
exclude_database_list: databases that do not need to synchronize, split with ,. The default setting is to exclude no databases. The database names are case-sensitive.
If there is overlap between
include_database_listandexclude_database_list,exclude_database_listwill take precedence overinclude_database_list.To connect to JDBC data sources, these two properties should work with
only_specified_database. See JDBC for more details.
Metadata refresh
By default, metadata changes in external catalogs, such as creating and dropping tables, adding and dropping columns, etc., will not be synchronized to Doris.
Users can refresh metadata in the following ways.
Manual refresh
Users need to manually refresh the metadata through the REFRESH command.
Regular refresh
When creating the catalog, specify the refresh time parameter metadata_refresh_interval_sec in the properties. It is measured in seconds. If this is set when creating the catalog, the FE master node will refresh the catalog regularly accordingly. Currently, Doris supports regular refresh for three types of catalogs:
- hms: Hive MetaStore
- es: Elasticsearch
- Jdbc: standard interface for database access (JDBC)
-- Set the catalog refresh interval to 20 seconds
CREATE CATALOG es PROPERTIES (
"type"="es",
"hosts"="http://127.0.0.1:9200",
"metadata_refresh_interval_sec"="20"
);
Auto Refresh
Currently Doris supports auto-refresh for Hive Catalog.
