Cross Cluster Replication (CCR)
Overview
Cross Cluster Replication (CCR) enables the synchronization of data changes from a source cluster to a target cluster at the database/table level. This feature can be used to ensure data availability for online services, isolate offline and online workloads, and build multiple data centers across various sites.
CCR is applicable to the following scenarios:
- Disaster recovery: This involves backing up enterprise data to another cluster and data center. In the event of a sudden incident causing business interruption or data loss, companies can recover data from the backup or quickly switch to the backup cluster. Disaster recovery is typically a must-have feature in use cases with high SLA requirements, such as those in finance, healthcare, and e-commerce.
- Read/write separation: This is to isolate querying and writing operations to reduce their mutual impact and improve resource utilization. For example, in cases of high writing pressure or high concurrency, read/write separation can distribute read and write operations to read-only and write-only database instances in various regions. This helps ensure high database performance and stability.
- Data transfer between headquarters and branch offices: In order to have unified data control and analysis within a corporation, the headquarters usually requires timely data synchronization from branch offices located in different regions. This avoids management confusion and wrong decision-making based on inconsistent data.
- Isolated upgrades: During system cluster upgrades, there might be a need to roll back to a previous version. Many traditional upgrade methods do not allow rolling back due to incompatible metadata. CCR in Doris can address this issue by building a standby cluster for upgrade and conducting dual-running verification. Users can ungrade the clusters one by one. CCR is not dependent on specific versions, making version rollback feasible.
Design
Concepts
-
Source cluster: the cluster where business data is written and originates from, requiring Doris version 2.0
-
Target cluster: the destination cluster for cross cluster replication, requiring version 2.0
-
Binlog: the change log of the source cluster, including schema and data changes
-
Syncer: a lightweight process
Architecture description
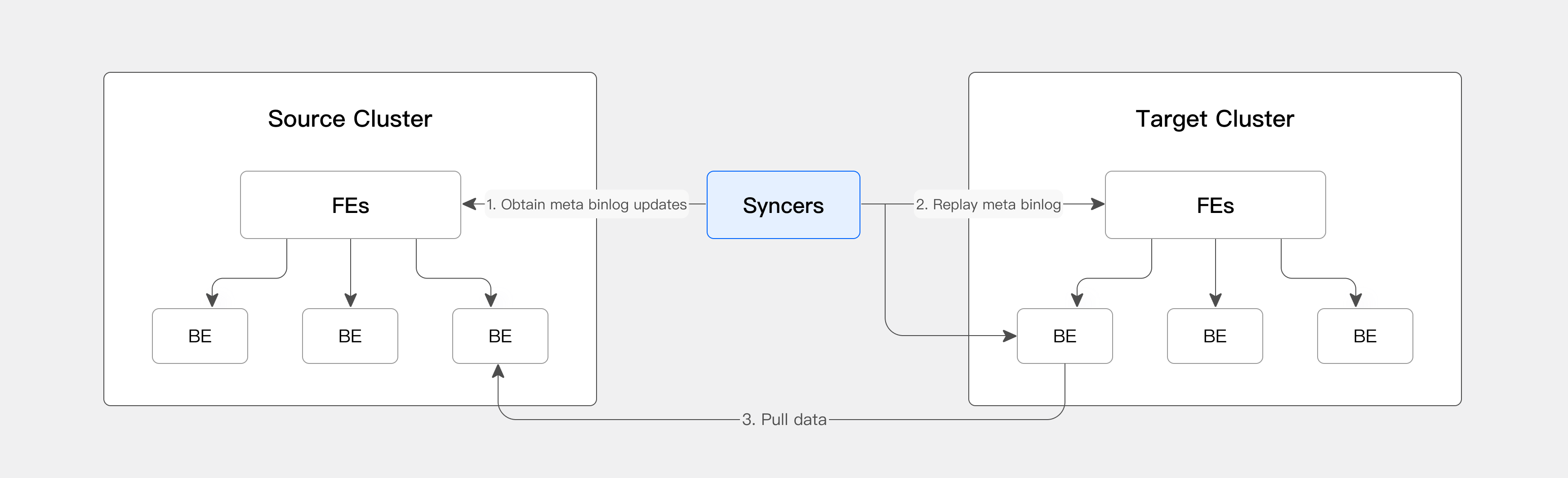
CCR relies on a lightweight process called syncer. Syncers retrieve binlogs from the source cluster, directly apply the metadata to the target cluster, and notify the target cluster to pull data from the source cluster. CCR allows both full and incremental data migration.
Usage
The usage of CCR is straightforward. Simply start the syncer service and send a command, and the syncers will take care of the rest.
- Deploy the source Doris cluster.
- Deploy the target Doris cluster.
- Both the source and target clusters need to enable binlog. Configure the following information in the fe.conf and be.conf files of the source and target clusters:
enable_feature_binlog=true
- Deploy syncers
Build CCR syncer
git clone https://github.com/selectdb/ccr-syncer
cd ccr-syncer
bash build.sh <-j NUM_OF_THREAD> <--output SYNCER_OUTPUT_DIR>
cd SYNCER_OUTPUT_DIR# Contact the Doris community for a free CCR binary package
Start and stop syncer
# Start
cd bin && sh start_syncer.sh --daemon
# Stop
sh stop_syncer.sh
- Enable binlog in the source cluster.
-- If you want to synchronize the entire database, you can execute the following script:
vim shell/enable_db_binlog.sh
Modify host, port, user, password, and db in the source cluster
Or ./enable_db_binlog.sh --host $host --port $port --user $user --password $password --db $db
-- If you want to synchronize a single table, you can execute the following script and enable binlog for the target table:
ALTER TABLE enable_binlog SET ("binlog.enable" = "true");
- Launch a synchronization task to the syncer
curl -X POST -H "Content-Type: application/json" -d '{
"name": "ccr_test",
"src": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "your_db_name",
"table": "your_table_name"
},
"dest": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "your_db_name",
"table": "your_table_name"
}
}' http://127.0.0.1:9190/create_ccr
Parameter description:
name: name of the CCR synchronization task, should be unique
host, port: host and mysql(jdbc) port for the master FE for the corresponding cluster
user, password: the credentials used by the syncer to initiate transactions, fetch data, etc.
If it is synchronization at the database level, specify your_db_name and leave your_table_name empty
If it is synchronization at the table level, specify both your_db_name and your_table_name
The synchronization task name can only be used once.
Operation manual for syncer
Start syncer
Start syncer according to the configurations and save a pid file in the default or specified path. The name of the pid file should follow host_port.pid.
Output file structure
The file structure can be seen under the output path after compilation:
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # Generated after running with the default configurations.
log
[ccr_syncer.log] # Generated after running with the default configurations.
The start_syncer.sh in the following text refers to the start_syncer.sh under its corresponding path.
Start options
--daemon
Run syncer in the background, set to false by default.
bash bin/start_syncer.sh --daemon
--db_type
Syncer can currently use two databases to store its metadata, sqlite3 (for local storage) and mysql (for local or remote storage).
bash bin/start_syncer.sh --db_type mysql
The default value is sqlite3.
When using MySQL to store metadata, syncer will use CREATE IF NOT EXISTS to create a database called ccr, where the metadata table related to CCR will be saved.
--db_dir
This option only works when db uses sqlite3****.
It allows you to specify the name and path of the db file generated by sqlite3.
bash bin/start_syncer.sh --db_dir /path/to/ccr.db
The default path is SYNCER_OUTPUT_DIR/db and the default file name is ccr.db.
--db_host & db_port & db_user & db_password
This option only works when db uses mysql****.
bash bin/start_syncer.sh --db_host 127.0.0.1 --db_port 3306 --db_user root --db_password "qwe123456"
The default values of db_host and db_port are shown in the example. The default values of db_user and db_password are empty.
--log_dir
Output path of the logs:
bash bin/start_syncer.sh --log_dir /path/to/ccr_syncer.log
The default path isSYNCER_OUTPUT_DIR/log and the default file name is ccr_syncer.log.
--log_level
Used to specify the output level of syncer logs.
bash bin/start_syncer.sh --log_level info
The format of the log is as follows, where the hook will only be printed when log_level > info :
# time level msg hooks
[2023-07-18 16:30:18] TRACE This is trace type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] DEBUG This is debug type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] INFO This is info type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] WARN This is warn type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] ERROR This is error type. ccrName=xxx line=xxx
[2023-07-18 16:30:18] FATAL This is fatal type. ccrName=xxx line=xxx
Under --daemon, the default value of log_level is info.
When running in the foreground, log_level defaults to trace, and logs are saved to log_dir using the tee command.
--host && --port
Used to specify the host and port of syncer, where host only plays the role of distinguishing itself in the cluster, which can be understood as the name of syncer, and the name of syncer in the cluster is host: port.
bash bin/start_syncer.sh --host 127.0.0.1 --port 9190
The default value of host is 127.0.0.1, and the default value of port is 9190.
--pid_dir
Used to specify the storage path of the pid file
The pid file is the credentials for closing the syncer. It is used in the stop_syncer.sh script. It saves the corresponding syncer process number. In order to facilitate management of syncer, you can specify the storage path of the pid file.
bash bin/start_syncer.sh --pid_dir /path/to/pids
The default value is SYNCER_OUTPUT_DIR/bin.
Stop syncer
Stop the syncer according to the process number in the pid file under the default or specified path. The name of the pid file should follow host_port.pid.
Output file structure
The file structure can be seen under the output path after compilation:
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # Generated after running with the default configurations.
log
[ccr_syncer.log] # Generated after running with the default configurations.
The start_syncer.sh in the following text refers to the start_syncer.sh under its corresponding path.
Stop options
Syncers can be stopped in three ways:
- Stop a single syncer in the directory
Specify the host and port of the syncer to be stopped. Be sure to keep it consistent with the host specified when start_syncer
- Batch stop the specified syncers in the directory
Specify the names of the pid files to be stopped, wrap the names in "" and separate them with spaces.
- Stop all syncers in the directory
Follow the default configurations.
--pid_dir
Specify the directory where the pid file is located. The above three stopping methods all depend on the directory where the pid file is located for execution.
bash bin/stop_syncer.sh --pid_dir /path/to/pids
The effect of the above example is to close the syncers corresponding to all pid files under /path/to/pids ( method 3 ). -- pid_dir can be used in combination with the above three syncer stopping methods.
The default value is SYNCER_OUTPUT_DIR/bin.
--host && --port
Stop the syncer corresponding to host: port in the pid_dir path.
bash bin/stop_syncer.sh --host 127.0.0.1 --port 9190
The default value of host is 127.0.0.1, and the default value of port is empty. That is, specifying the host alone will degrade method 1 to method 3. Method 1 will only take effect when neither the host nor the port is empty.
--files
Stop the syncer corresponding to the specified pid file name in the pid_dir path.
bash bin/stop_syncer.sh --files "127.0.0.1_9190.pid 127.0.0.1_9191.pid"
The file names should be wrapped in " " and separated with spaces.
Syncer operations
Template for requests
curl -X POST -H "Content-Type: application/json" -d {json_body} http://ccr_syncer_host:ccr_syncer_port/operator
json_body: send operation information in JSON format
operator: different operations for syncer
The interface returns JSON. If successful, the "success" field will be true. Conversely, if there is an error, it will be false, and then there will be an ErrMsgs field.
{"success":true}
or
{"success":false,"error_msg":"job ccr_test not exist"}
Operators
- create_ccr
Create CCR tasks
curl -X POST -H "Content-Type: application/json" -d '{
"name": "ccr_test",
"src": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "demo",
"table": "example_tbl"
},
"dest": {
"host": "localhost",
"port": "9030",
"thrift_port": "9020",
"user": "root",
"password": "",
"database": "ccrt",
"table": "copy"
}
}' http://127.0.0.1:9190/create_ccr
-
name: the name of the CCR synchronization task, should be unique
-
host, port: correspond to the host and mysql (jdbc) port of the cluster's master
-
thrift_port: corresponds to the rpc_port of the FE
-
user, password: the credentials used by the syncer to initiate transactions, fetch data, etc.
-
database, table:
- If it is a database-level synchronization, fill in the database name and leave the table name empty.
- If it is a table-level synchronization, specify both the database name and the table name.
-
get_lag
View the synchronization progress.
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/get_lag
The job_name is the name specified when create_ccr.
- pause
Pause synchronization task.
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/pause
- resume
Resume synchronization task.
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/resume
- delete
Delete synchronization task.
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/delete
- version
View version information.
curl http://ccr_syncer_host:ccr_syncer_port/version
# > return
{"version": "2.0.1"}
- job status
View job status.
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/job_status
{
"success": true,
"status": {
"name": "ccr_db_table_alias",
"state": "running",
"progress_state": "TableIncrementalSync"
}
}
- desync job
No sync. Users can swap the source and target clusters.
curl -X POST -H "Content-Type: application/json" -d '{
"name": "job_name"
}' http://ccr_syncer_host:ccr_syncer_port/desync
- list_jobs
List all created tasks.
curl http://ccr_syncer_host:ccr_syncer_port/list_jobs
{"success":true,"jobs":["ccr_db_table_alias"]}
Open binlog for all tables in the database
Output file structure
The file structure can be seen under the output path after compilation:
output_dir
bin
ccr_syncer
enable_db_binlog.sh
start_syncer.sh
stop_syncer.sh
db
[ccr.db] # Generated after running with the default configurations.
log
[ccr_syncer.log] # Generated after running with the default configurations.
The start_syncer.sh in the following text refers to the start_syncer.sh under its corresponding path.
Usage
bash bin/enable_db_binlog.sh -h host -p port -u user -P password -d db
High availability of syncer
The high availability of syncers relies on MySQL. If MySQL is used as the backend storage, the syncer can discover other syncers. If one syncer crashes, the others will take over its tasks.
Privilege requirements
select_priv: read-only privileges for databases and tablesload_priv: write privileges for databases and tables, including load, insert, delete, etc.alter_priv: privilege to modify databases and tables, including renaming databases/tables, adding/deleting/changing columns, adding/deleting partitions, etc.create_priv: privilege to create databases, tables, and viewsdrop_priv: privilege to drop databases, tables, and views
Admin privileges are required (We are planning on removing this in future versions). This is used to check the enable binlog config.
Usage restrictions
Network constraints
- Syncer needs to have connectivity to both the upstream and downstream FEs and BEs.
- The downstream BE should have connectivity to the upstream BE.
- The external IP and Doris internal IP should be the same. In other words, the IP address visible in the output of
show frontends/backendsshould be the same IP that can be directly connected to. It should not involve IP forwarding or NAT for direct connections.
ThriftPool constraints
It is recommended to increase the size of the Thrift thread pool to a number greater than the number of buckets involved in a single commit operation.
Version requirements
Minimum required version: V2.0.3
Unsupported operations
- Rename table
- Operations such as table drop-recovery
- Operations related to rename table, replace partition
- Concurrent backup/restore within the same database
Feature
Rate limit
BE-side configuration parameter
download_binlog_rate_limit_kbs=1024 # Limits the download speed of Binlog (including Local Snapshot) from the source cluster to 1 MB/s in a single BE node
-
The
download_binlog_rate_limit_kbsparameter is configured on the BE nodes of the source cluster. By setting this parameter, the data pull rate can be effectively limited. -
The
download_binlog_rate_limit_kbsparameter primarily controls the speed of data transfer for each single BE node. To calculate the overall cluster rate, one would multiply the parameter value by the number of nodes in the cluster.
IS_BEING_SYNCED
Doris v2.0 "is_being_synced" = "true"
During data synchronization using CCR, replica tables (referred to as target tables) are created in the target cluster for the tables within the synchronization scope of the source cluster (referred to as source tables). However, certain functionalities and attributes need to be disabled or cleared when creating replica tables to ensure the correctness of the synchronization process. For example:
- The source tables may contain information that is not synchronized to the target cluster, such as
storage_policy, which may cause the creation of the target table to fail or result in abnormal behavior. - The source tables may have dynamic functionalities, such as dynamic partitioning, which can lead to uncontrolled behavior in the target table and result in inconsistent partitions.
The attributes that need to be cleared during replication are:
storage_policycolocate_with
The functionalities that need to be disabled during synchronization are:
- Automatic bucketing
- Dynamic partitioning
Implementation
When creating the target table, the syncer controls the addition or deletion of the is_being_synced property. In CCR, there are two approaches to creating a target table:
- During table synchronization, the syncer performs a full copy of the source table using backup/restore to obtain the target table.
- During database synchronization, for existing tables, the syncer also uses backup/restore to obtain the target table. For incremental tables, the syncer creates the target table using the CreateTableRecord binlog.
Therefore, there are two entry points for inserting the is_being_synced property: the restore process during full synchronization and the getDdlStmt during incremental synchronization.
During the restoration process of full synchronization, the syncer initiates a restore operation of the snapshot from the source cluster via RPC. During this process, the is_being_synced property is added to the RestoreStmt and takes effect in the final restoreJob, executing the relevant logic for is_being_synced.
During incremental synchronization, add the boolean getDdlForSync parameter to the getDdlStmt method to differentiate whether it is a controlled transformation to the target table DDL, and execute the relevant logic for isBeingSynced during the creation of the target table.
Regarding the disabling of the functionalities mentioned above:
- Automatic bucketing: Automatic bucketing is enabled when creating a table. It calculates the appropriate number of buckets. This may result in a mismatch in the number of buckets between the source and target tables. Therefore, during synchronization, obtain the number of buckets from the source table, as well as the information about whether the source table is an automatic bucketing table in order to restore the functionality after synchronization. The current recommended approach is to default the autobucket attribute to false when retrieving distribution information. During table restoration, check the
_auto_bucketattribute to find out if the source table is an automatic bucketing table. If it is, set the target table's autobucket field to true to bypass the calculation of bucket numbers and directly apply the number of buckets from the source table to the target table. - Dynamic partitioning: This is implemented by adding
olapTable.isBeingSynced()to the condition for executing add/drop partition operations. This ensures that the target table does not perform periodic add/drop partition operations during synchronization.
Note
The is_being_synced property should be fully controlled by the syncer, and users should not modify this property manually unless there are exceptional circumstances.
