Introduction to Apache Doris
Apache Doris is a high-performance, real-time analytical database based on MPP architecture, known for its extreme speed and ease of use. It only requires a sub-second response time to return query results under massive data and can support not only high-concurrent point query scenarios but also high-throughput complex analysis scenarios. All this makes Apache Doris an ideal tool for scenarios including report analysis, ad-hoc query, unified data warehouse, and data lake query acceleration. On Apache Doris, users can build various applications, such as user behavior analysis, AB test platform, log retrieval analysis, user portrait analysis, and order analysis.
Apache Doris, formerly known as Palo, was initially created to support Baidu's ad reporting business. It was officially open-sourced in 2017 and donated by Baidu to the Apache Foundation for incubation in July 2018, where it was operated by members of the incubator project management committee under the guidance of Apache mentors. Currently, the Apache Doris community has gathered more than 400 contributors from hundreds companies in different industries, and the number of active contributors is more than 100 per month. In June 2022, Apache Doris graduated from Apache incubator as a Top-Level Project.
Apache Doris now has a wide user base in China and around the world, and as of today, Apache Doris is used in production environments in over 2000 companies worldwide. Of the top 50 Chinese Internet companies by market capitalization (or valuation), more than 80% are long-term users of Apache Doris, including Baidu, Meituan, Xiaomi, Jingdong, Bytedance, Tencent, NetEase, Kwai, Weibo, and Ke Holdings. It is also widely used in some traditional industries such as finance, energy, manufacturing, and telecommunications.
Usage Scenarios
As shown in the figure below, after various data integration and processing, the data sources are usually stored in the real-time data warehouse Doris and the offline data lake or data warehouse (in Apache Hive, Apache Iceberg or Apache Hudi).
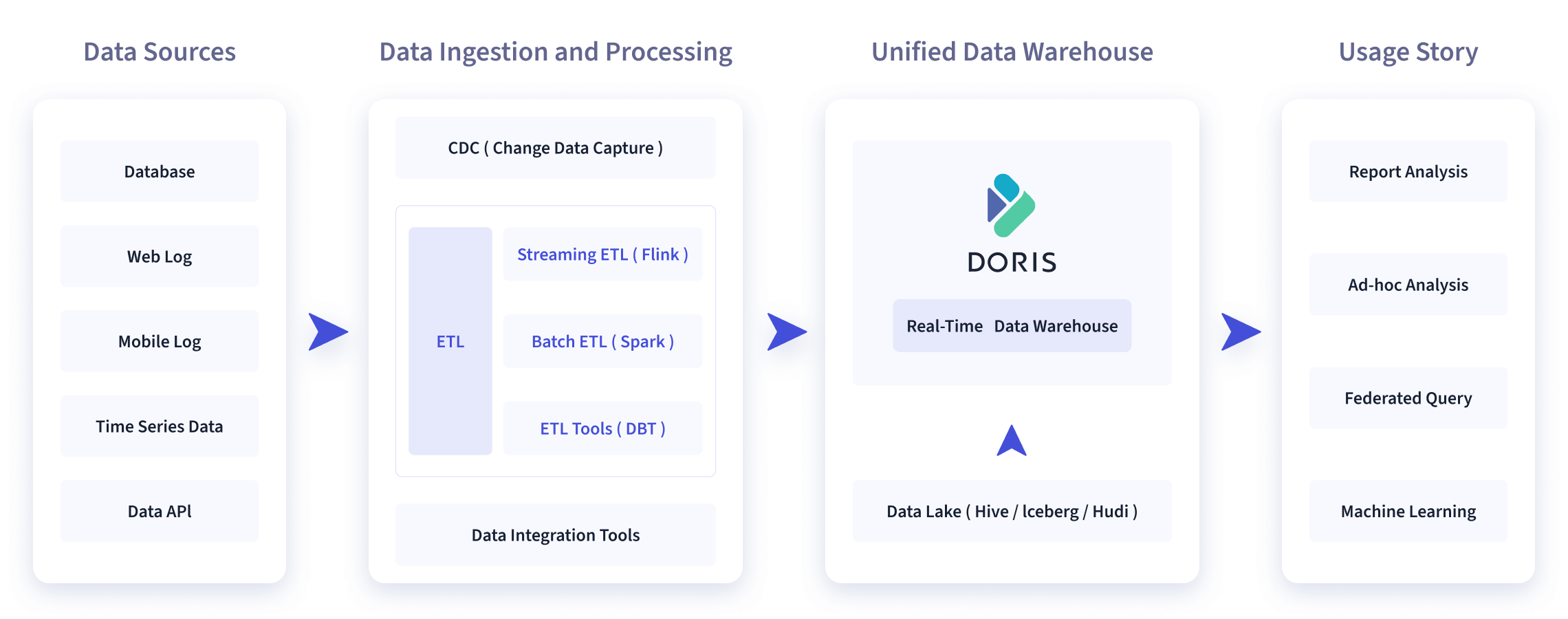
Apache Doris is widely used in the following scenarios:
-
Reporting Analysis
- Real-time dashboards
- Reports for in-house analysts and managers
- Highly concurrent user-oriented or customer-oriented report analysis: such as website analysis and ad reporting that usually require thousands of QPS and quick response times measured in miliseconds. A successful user case is that Doris has been used by the Chinese e-commerce giant JD.com in ad reporting, where it receives 10 billion rows of data per day, handles over 10,000 QPS, and delivers a 99 percentile query latency of 150 ms.
-
Ad-Hoc Query. Analyst-oriented self-service analytics with irregular query patterns and high throughput requirements. XiaoMi has built a growth analytics platform (Growth Analytics, GA) based on Doris, using user behavior data for business growth analysis, with an average query latency of 10 seconds and a 95th percentile query latency of 30 seconds or less, and tens of thousands of SQL queries per day.
-
Unified Data Warehouse Construction. Apache Doris allows users to build a unified data warehouse via one single platform and save the trouble of handling complicated software stacks. Chinese hot pot chain Haidilao has built a unified data warehouse with Doris to replace its old complex architecture consisting of Apache Spark, Apache Hive, Apache Kudu, Apache HBase, and Apache Phoenix.
-
Data Lake Query. Apache Doris avoids data copying by federating the data in Apache Hive, Apache Iceberg, and Apache Hudi using external tables, and thus achieves outstanding query performance.
Technical Overview
As shown in the figure below, the Apache Doris architecture is simple and neat, with only two types of processes.
- Frontend (FE): user request access, query parsing and planning, metadata management, node management, etc.
- Backend (BE): data storage and query plan execution
Both types of processes are horizontally scalable, and a single cluster can support up to hundreds of machines and tens of petabytes of storage capacity. And these two types of processes guarantee high availability of services and high reliability of data through consistency protocols. This highly integrated architecture design greatly reduces the operation and maintenance cost of a distributed system.
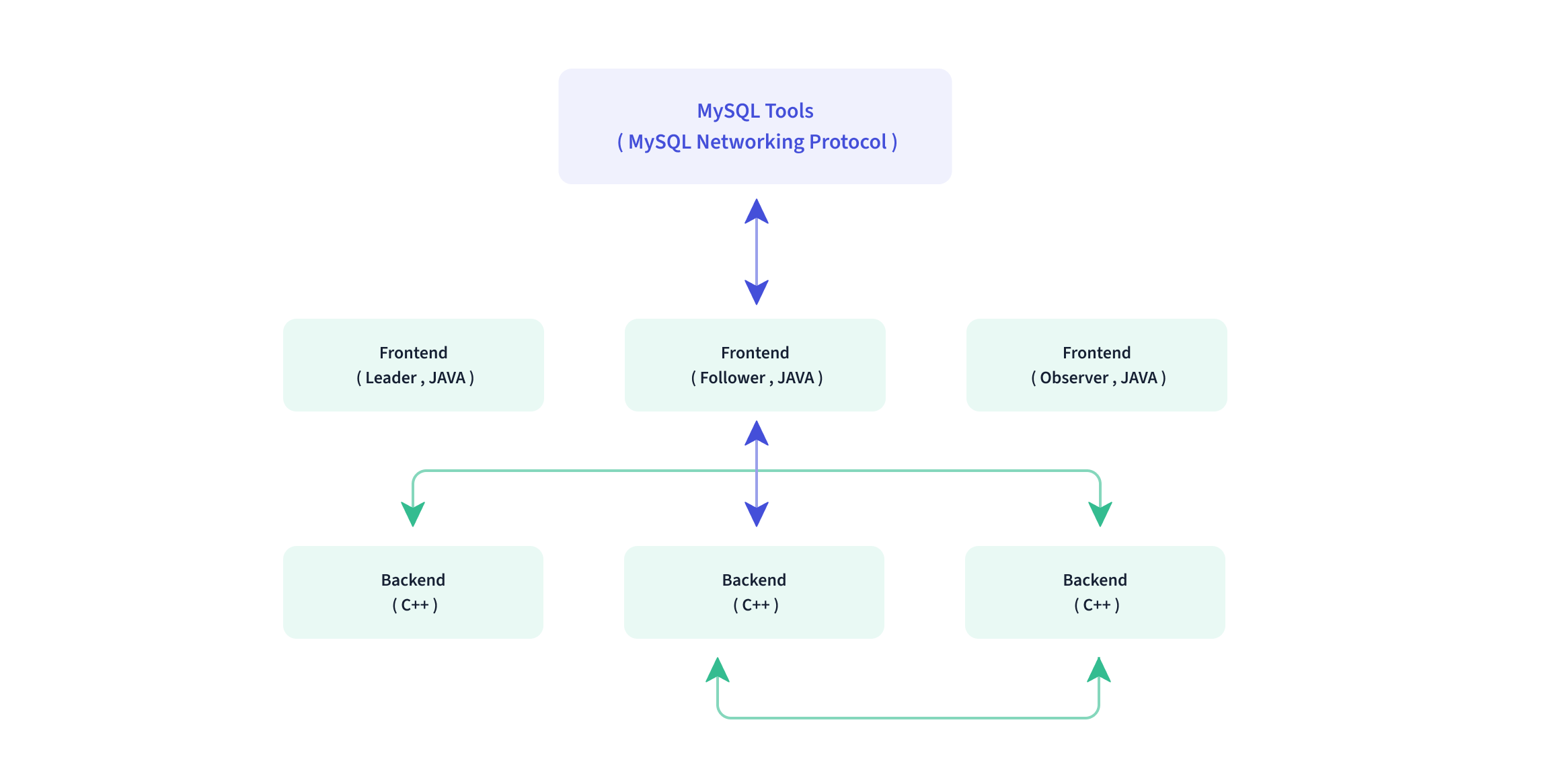
In terms of interfaces, Apache Doris adopts MySQL protocol, supports standard SQL, and is highly compatible with MySQL dialect. Users can access Doris through various client tools and it supports seamless connection with BI tools.
Doris uses a columnar storage engine, which encodes, compresses, and reads data by column. This enables a very high compression ratio and largely reduces irrelavant data scans, thus making more efficient use of IO and CPU resources.
Doris supports various index structures to minimize data scans:
- Sorted Compound Key Index: Users can specify three columns at most to form a compound sort key. This can effectively prune data to better support highly concurrent reporting scenarios.
- Z-order Index: This allows users to efficiently run range queries on any combination of fields in their schema.
- MIN/MAX Indexing: This enables effective filtering of equivalence and range queries for numeric types.
- Bloom Filter: very effective in equivalence filtering and pruning of high cardinality columns
- Invert Index: This enables fast search for any field.
Doris supports a variety of storage models and has optimized them for different scenarios:
- Aggregate Key Model: able to merge the value columns with the same keys and significantly improve performance
- Unique Key Model: Keys are unique in this model and data with the same key will be overwritten to achieve row-level data updates.
- Duplicate Key Model: This is a detailed data model capable of detailed storage of fact tables.
Doris also supports strongly consistent materialized views. Materialized views are automatically selected and updated, which greatly reduces maintenance costs for users.
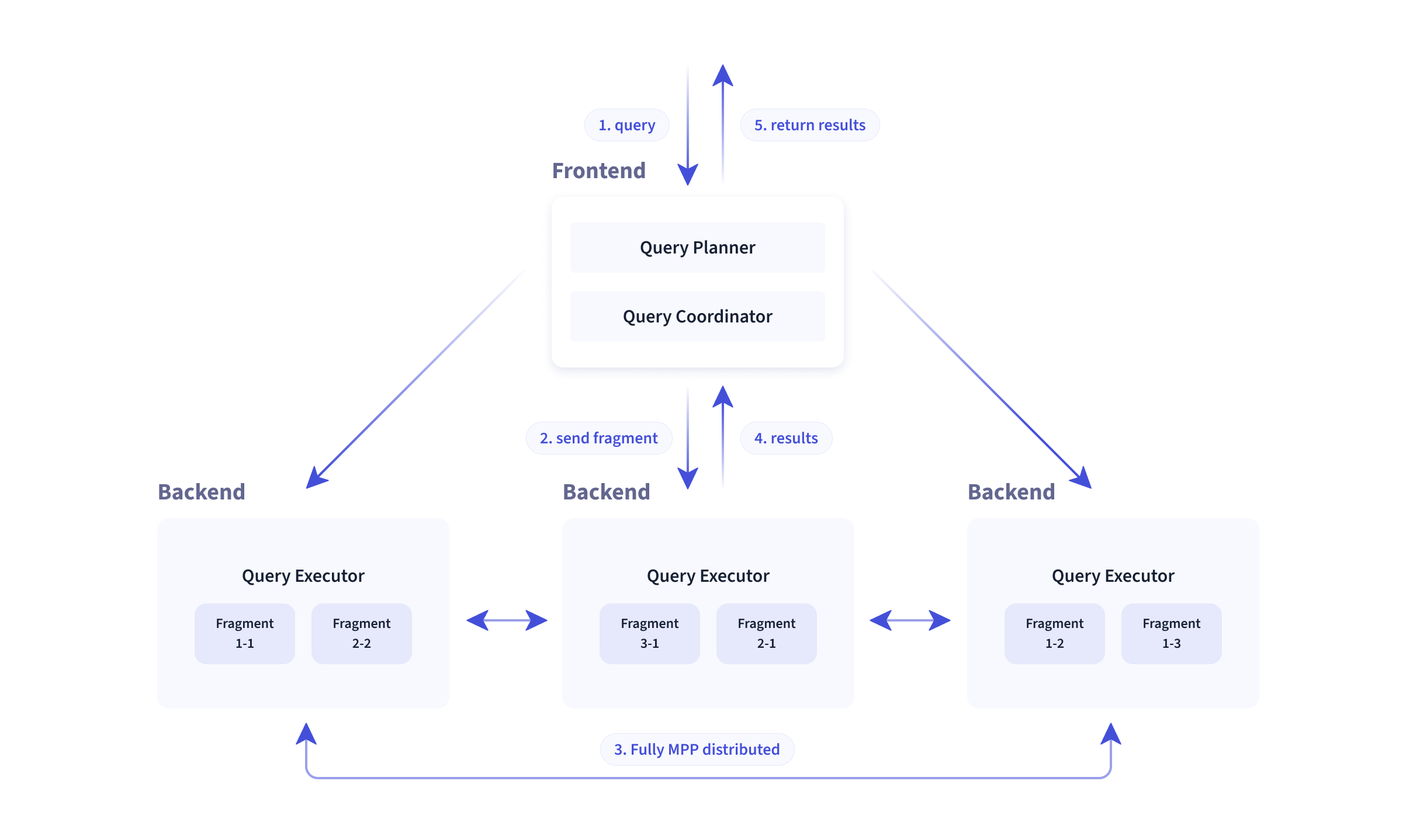
Doris adopts the MPP model in its query engine to realize parallel execution between and within nodes. It also supports distributed shuffle join for multiple large tables so as to handle complex queries.
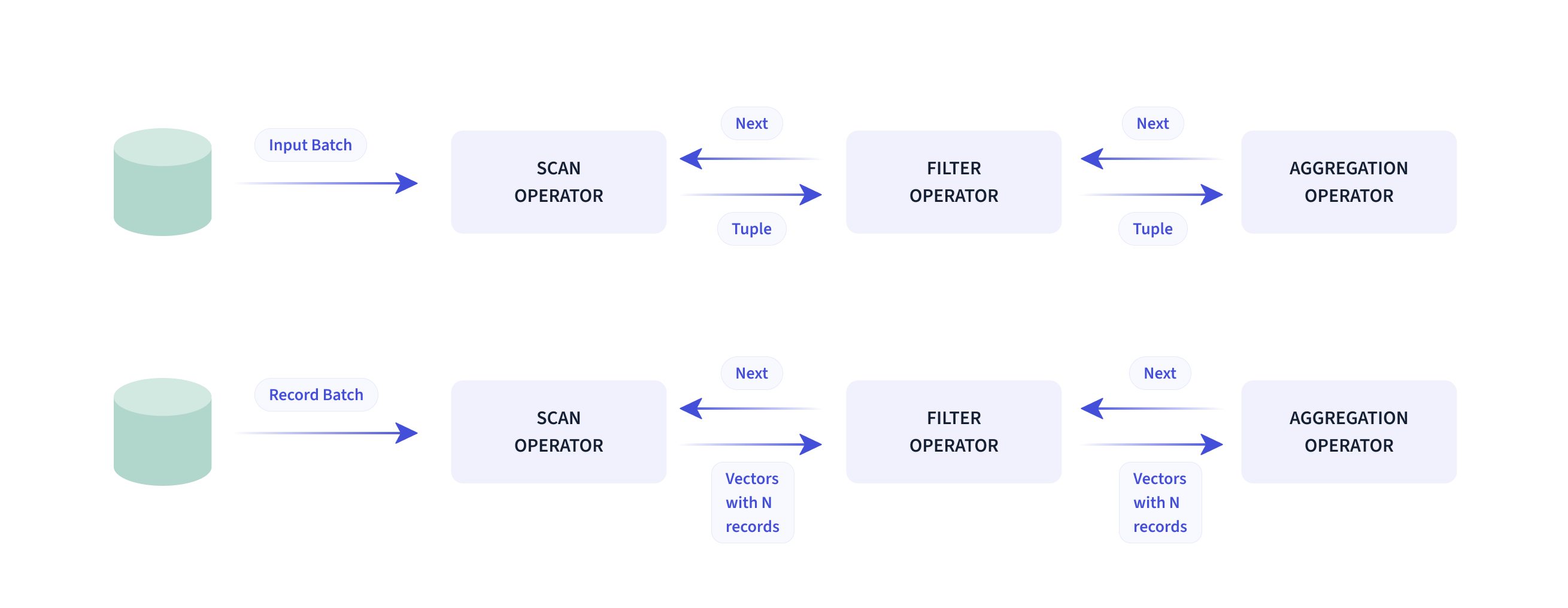
The Doris query engine is vectorized, with all memory structures laid out in a columnar format. This can largely reduce virtual function calls, improve cache hit rates, and make efficient use of SIMD instructions. Doris delivers a 5–10 times higher performance in wide table aggregation scenarios than non-vectorized engines.
Apache Doris uses Adaptive Query Execution technology to dynamically adjust the execution plan based on runtime statistics. For example, it can generate runtime filter, push it to the probe side, and automatically penetrate it to the Scan node at the bottom, which drastically reduces the amount of data in the probe and increases join performance. The runtime filter in Doris supports In/Min/Max/Bloom filter.
In terms of optimizers, Doris uses a combination of CBO and RBO. RBO supports constant folding, subquery rewriting, predicate pushdown and CBO supports Join Reorder. The Doris CBO is under continuous optimization for more accurate statistical information collection and derivation, and more accurate cost model prediction.
