BloomFilter index
BloomFilter is a fast search algorithm for multi-hash function mapping proposed by Bloom in 1970. Usually used in some occasions where it is necessary to quickly determine whether an element belongs to a set, but is not strictly required to be 100% correct, BloomFilter has the following characteristics:
- A highly space-efficient probabilistic data structure used to check whether an element is in a set.
- For a call to detect whether an element exists, BloomFilter will tell the caller one of two results: it may exist or it must not exist.
- The disadvantage is that there is a misjudgment, telling you that it may exist, not necessarily true.
Bloom filter is actually composed of an extremely long binary bit array and a series of hash functions. The binary bit array is all 0 initially. When an element to be queried is given, this element will be calculated by a series of hash functions to map out a series of values, and all values are treated as 1 in the offset of the bit array.
Figure below shows an example of Bloom Filter with m=18, k=3 (m is the size of the Bit array, and k is the number of Hash functions). The three elements of x, y, and z in the set are hashed into the bit array through three different hash functions. When querying the element w, after calculating by the Hash function, because one bit is 0, w is not in the set.
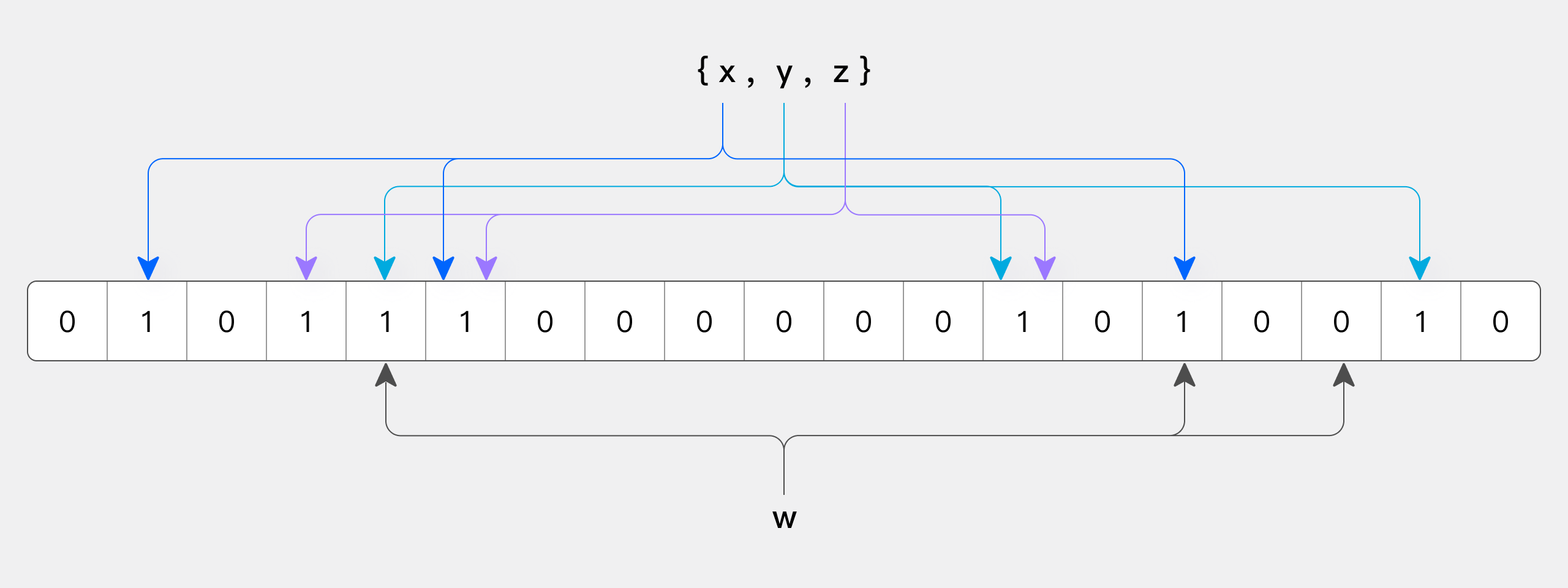
So how to judge whether the plot and the elements are in the set? Similarly, all the offset positions of this element are obtained after hash function calculation. If these positions are all 1, then it is judged that this element is in this set, if one is not 1, then it is judged that this element is not in this set. It's that simple!
Doris BloomFilter index and usage scenarios
When we use HBase, we know that the Hbase data block index provides an effective method to find the data block of the HFile that should be read when accessing a specific row. But its utility is limited. The default size of the HFile data block is 64KB, and this size cannot be adjusted too much.
If you are looking for a short row, only building an index on the starting row key of the entire data block cannot give you fine-grained index information. For example, if your row occupies 100 bytes of storage space, a 64KB data block contains (64 * 1024)/100 = 655.53 = ~700 rows, and you can only put the starting row on the index bit. The row you are looking for may fall in the row interval on a particular data block, but it is not necessarily stored in that data block. There are many possibilities for this, or the row does not exist in the table, or it is stored in another HFile, or even in MemStore. In these cases, reading data blocks from the hard disk will bring IO overhead and will abuse the data block cache. This can affect performance, especially when you are facing a huge data set and there are many concurrent users.
So HBase provides Bloom filters that allow you to do a reverse test on the data stored in each data block. When a row is requested, first check the Bloom filter to see if the row is not in this data block. The Bloom filter must either confirm that the line is not in the answer, or answer that it doesn't know. This is why we call it a reverse test. Bloom filters can also be applied to the cells in the row. Use the same reverse test first when accessing a column of identifiers.
Bloom filters are not without cost. Storing this additional index level takes up additional space. Bloom filters grow as their index object data grows, so row-level bloom filters take up less space than column identifier-level bloom filters. When space is not an issue, they can help you squeeze the performance potential of the system.
The BloomFilter index of Doris is specified when the table is built, or completed by the ALTER operation of the table. Bloom Filter is essentially a bitmap structure, used to quickly determine whether a given value is in a set. This judgment will produce a small probability of misjudgment. That is, if it returns false, it must not be in this set. And if the range is true, it may be in this set.
The BloomFilter index is also created with Block as the granularity. In each Block, the value of the specified column is used as a set to generate a BloomFilter index entry, which is used to quickly filter the data that does not meet the conditions in the query.
Let's take a look at how Doris creates BloomFilter indexes through examples.
Create BloomFilter Index
The Doris BloomFilter index is created by adding "bloom_filter_columns"="k1,k2,k3" to the PROPERTIES of the table building statement, this attribute, k1,k2,k3 is the Key column name of the BloomFilter index you want to create, for example, we Create a BloomFilter index for the saler_id and category_id in the table.
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "Sales time",
customer_id int NOT NULL COMMENT "Customer ID",
saler_id int NOT NULL COMMENT "Salesperson",
sku_id int NOT NULL COMMENT "Product ID",
category_id int NOT NULL COMMENT "Product Category",
sale_count int NOT NULL COMMENT "Sales Quantity",
sale_price DECIMAL(12,2) NOT NULL COMMENT "unit price",
sale_amt DECIMAL(20,2) COMMENT "Total sales amount"
)
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
PARTITION BY RANGE(sale_date)
(
PARTITION P_202111 VALUES [('2021-11-01'), ('2021-12-01'))
)
DISTRIBUTED BY HASH(saler_id) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"bloom_filter_columns"="saler_id,category_id",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "MONTH",
"dynamic_partition.time_zone" = "Asia/Shanghai",
"dynamic_partition.start" = "-2147483648",
"dynamic_partition.end" = "2",
"dynamic_partition.prefix" = "P_",
"dynamic_partition.replication_num" = "3",
"dynamic_partition.buckets" = "3"
);
View BloomFilter Index
Check that the BloomFilter index we built on the table is to use:
SHOW CREATE TABLE <table_name>;
Delete BloomFilter index
Deleting the index is to remove the index column from the bloom_filter_columns attribute:
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");
Modify BloomFilter index
Modifying the index is to modify the bloom_filter_columns attribute of the table:
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");
Doris BloomFilter usage scenarios
You can consider establishing a Bloom Filter index for a column when the following conditions are met:
- First, BloomFilter is suitable for non-prefix filtering.
- The query will be filtered according to the high frequency of the column, and most of the query conditions are in and = filtering.
- Unlike Bitmap, BloomFilter is suitable for high cardinality columns. Such as UserID. Because if it is created on a low-cardinality column, such as a "gender" column, each Block will almost contain all values, causing the BloomFilter index to lose its meaning.
Doris BloomFilter use precautions
- It does not support the creation of Bloom Filter indexes for Tinyint, Float, and Double columns.
- The Bloom Filter index only has an acceleration effect on in and = filtering queries.
- If you want to check whether a query hits the Bloom Filter index, you can check the profile information of the query.
